Am Beispiel der Organigramme arbeiten wir derzeit an einer praxisnahen Fallstudie, um zu lernen, wie mit wichtigen Basis-Informationen die Grundlage für Linked Open Data in Berlin gelegt werden kann.
Auf dieser Seite
Einleitung
Dialog mit einem Bären
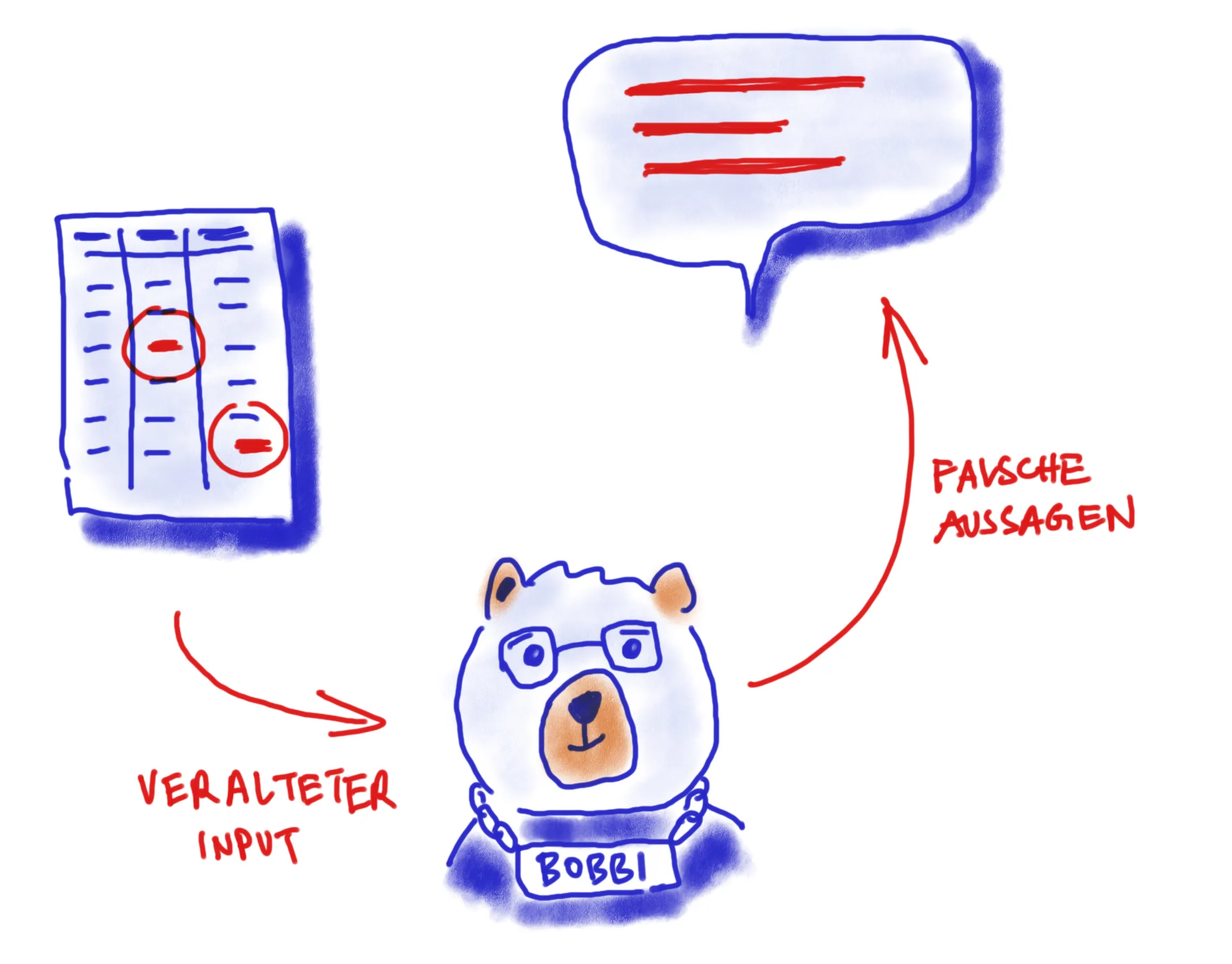
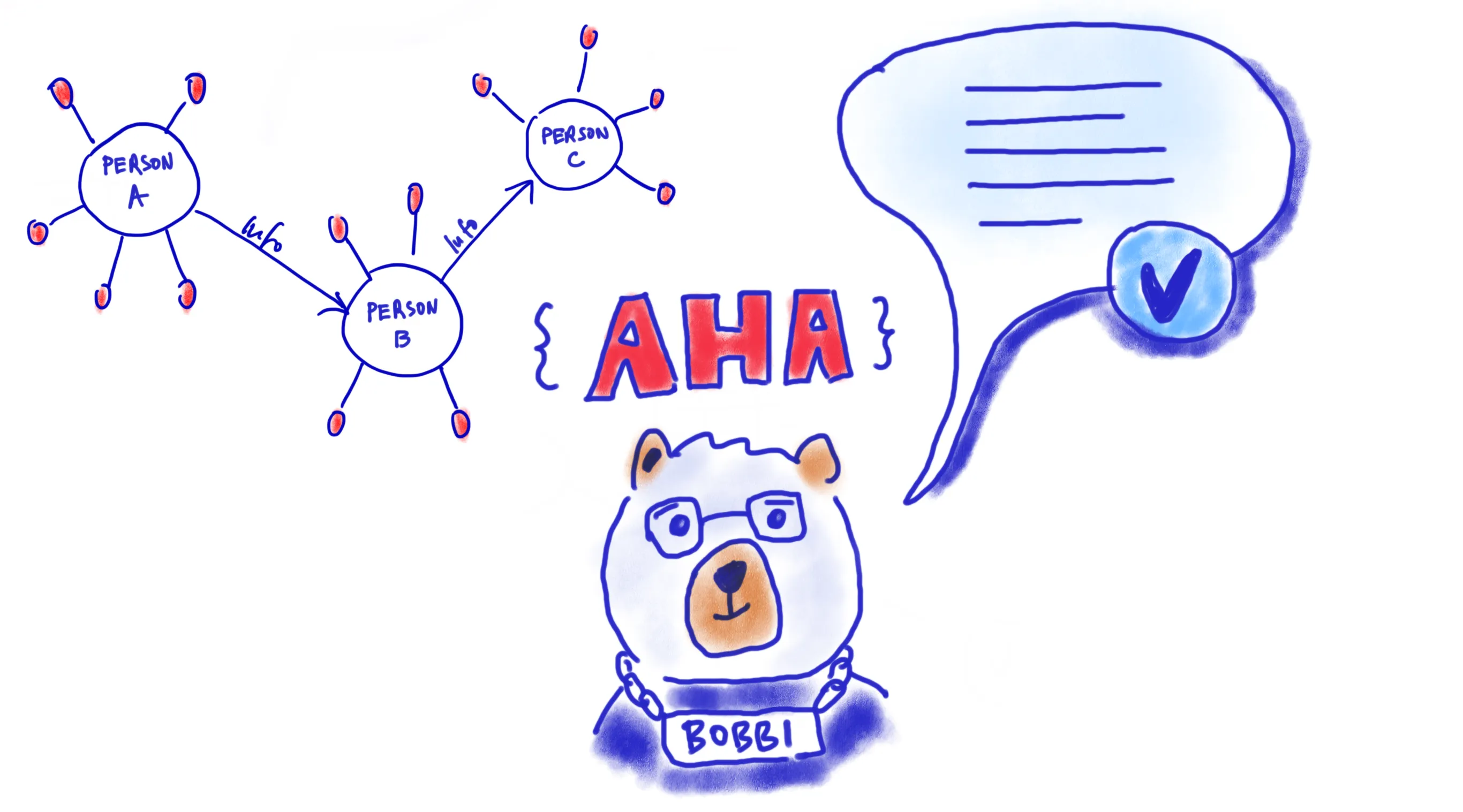
Ein Blick zurück ins Frühjahr 2023: Der Krimi um das Berliner Wahldebakel rückt langsam aus dem Rampenlicht der öffentlichen Berichterstattung.
Die darauffolgenden Wiederholungswahlen und der Regierungswechsel sind fast schon Geschichte, da sieht sich der Senat mit einer kleinen neuen Panne konfrontiert: Wie die Presse berichtet, scheint der Berliner Chatbot des Service-Portals, verkörpert durch einen Bären
namens „Bobbi“, auch mehrere Wochen nach der Wahl noch nicht auf dem neuesten Stand der politischen Entwicklungen zu sein. Trotz des Wechsels im
Amt des Regierenden Bürgermeisters zu Kai Wegner behauptet Bobbi felsenfest, Franziska Giffey sei Inhaberin dieses Amtes.
Zur gleichen Zeit und augenscheinlich im Kontrast stehend, diskutiert nicht nur die gesamte Technologiebranche über die massiven Potentiale durch die rasanten Entwicklungen im Bereich der künstlichen Intelligenz, angeregt durch Chatbots wie ChatGPT.
Also Bobbi, wer ist Regierender Bürgermeister in Berlin? „Die Regierende
Bürgermeisterin von Berlin ist Franziska Giffey.“ Ähh.. dann vielleicht so: Bobbi, wer
ist Kai Wegner? „Es tut mir sehr leid. Leider habe ich zu Ihrer Frage keine passende
Antwort gefunden.“
Problemstellung und Motivation - Garbage in, garbage out
So amüsant und harmlos die Anekdote um Bobbi auch wirkt, sie illustriert einen Aspekt sehr anschaulich:
Jeder Chatbot, ebenso wie jedes andere Softwareprogramm, jedes Webtool und jede Datenanalyse, sind zum einen zweckgebunden und werden für spezifische Aufgaben entwickelt, zum anderen sind sie auch nur so leistungsfähig und aussagekräftig, wie die Informationen und Daten, mit denen sie entsprechend des Use Cases gespeist werden.
Programme wie Chatbot Bobbi, sind nur so gut wie die ihnen zugrunde liegenden Informationen
In diesem Kontext steht Bobbi symbolisch weniger für geringen Innovationscharakter, als viel mehr für die Herausforderungen, mit denen digitale Assistenten beim Thema Nutzerinnenführung, Relevanz und Genauigkeit konfrontiert sein können.
Ein zentraler Aspekt, der künftig für Digitalprojekte sowie die Weiterentwicklung und Innovation innerhalb digitaler Ökosysteme eine immer größer werdende Rolle spielen wird, ist daher die Verfügbarkeit von qualitativ hochwertigen, aktuellen und maschinenlesbaren Informationen.
Vor diesem Hintergrund gewinnt das Konzept der Linked Open Data an Aufmerksamkeit, da es das Potenzial birgt, eine vernetzte und zugängliche Datenbasis zu schaffen, die eine Grundlage für präzisere und relevantere Digitalprojekte bilden kann.
Im Folgenden erklären wir, welche Potentiale in Linked Open Data stecken und wie wir als ODIS unser selbstentwickeltes Organigramm-Tool als praxisnahe Fallstudie nutzen. Dieses Beispiel soll nicht nur Bewegung in die Diskussion bringen, sondern auch als Ausgangspunkt für die Schaffung einer vernetzten Datenbasis für Berlin dienen. Und davon könnten nicht nur digitale Assistenten wie Bobbi profitieren.
Hintergrund
Die Ausgangslage: Informationssilos
Die Themenbereiche und Aufgaben der Berliner Verwaltung sind zahlreich. Ebenso vielfältig ist die Art und Weise, wie Informationen in der Verwaltung erhoben, gesammelt, verarbeitet und geteilt werden. Da gibt es Bereiche, in denen mit standardisierten und maschinenlesbaren Daten gearbeitet wird – zum Beispiel im Finanzsektor, wo Daten behördenübergreifend für Berechnungen und Planungen essenziell sind und in speziellen Fachverfahren verarbeitet werden.
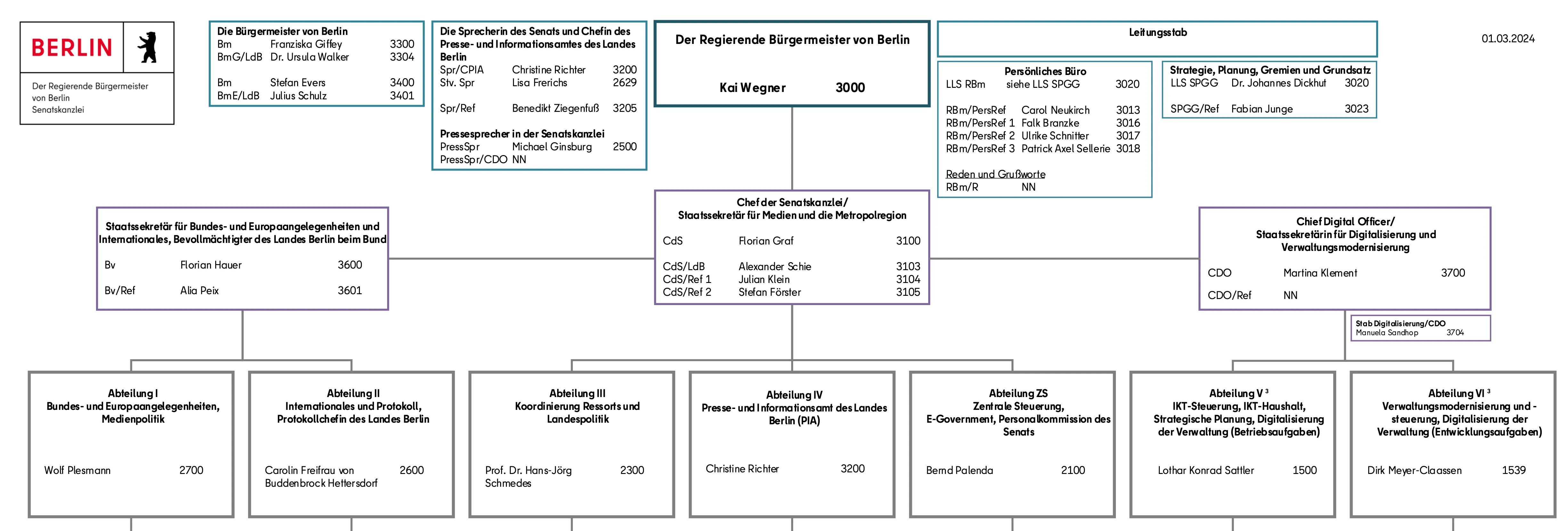
In anderen Bereichen dagegen gibt es weniger Vorgaben und abgestimmte Prozesse. Ein Beispiel hierfür sind die Zuständigkeiten und Strukturen in der Verwaltung. Die wichtigsten Personalien werden über die Organigramme der Senats- und Bezirksverwaltungen dargestellt und dezentral veröffentlicht. Diese wichtigen Informationen liegen in hoher Aktualität vor und können im Internet gefunden und eingesehen werden. Sie werden im PDF-Format veröffentlicht, folgen keinen einheitlichen Standards und sind mit einem Fokus auf die Lesbarkeit für Menschen erstellt.
Ausschnitt aus dem PDF-Organigramm der Senatskanzlei (März 2024).
Öffnet man beispielsweise das Organigramm der Senatskanzlei, kann ein Mensch auf einen Blick recht schnell erfassen, wer den Posten „Regierender Bürgermeister von Berlin“ innehat: Kai Wegner. Auch Franziska Giffey findet sich in diesem Organigramm, als „Bürgermeisterin von Berlin“ (also als seine Stellvertreterin). Durch einen Computer, bzw. Programmcode, ist dieses PDF nur schwer automatisiert auslesbar. Würden die Informationen der Organigramme dagegen in einer strukturierten Tabelle vorliegen, hätte der Computer es schon deutlich einfacher.
Informationen aus einer PDF können von Computerprogrammen nur sehr begrenzt verarbeitet werden.
Allerdings haben auch Tabellen ihre Grenzen. Im Fall der Organigramme ist das recht offensichtlich:
Die Verwaltungsstrukturen sind sehr komplex und geprägt von Hierarchien und Abhängigkeiten, die sich in einer tabellarischen Übersicht nur schwer abbilden lassen.
Ein weiteres Problem ist die Existenz vieler isolierter Datensätze in der Verwaltung. Ein Beispiel verdeutlicht dies:
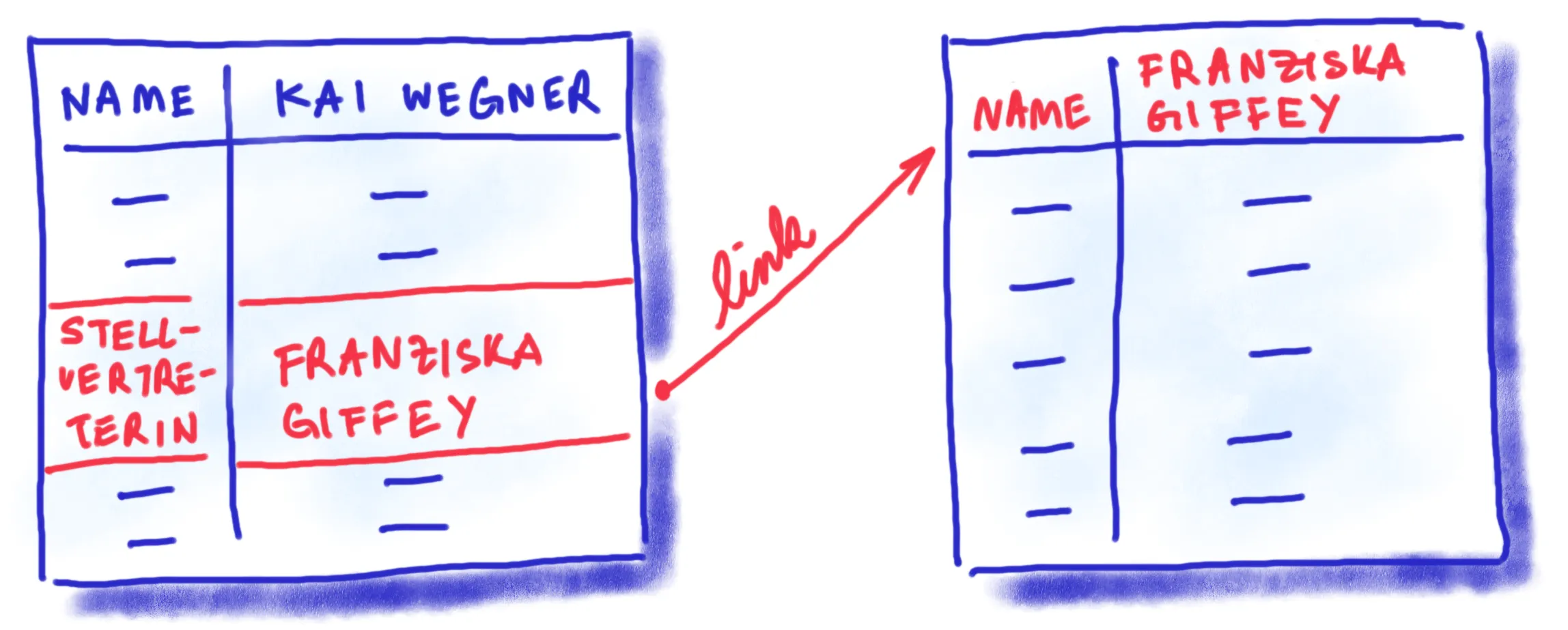
Angenommen, die Senatskanzlei veröffentlicht neben ihrem PDF-Organigramm eine maschinenlesbare Tabelle mit den Namen der Personen und deren Positionen.
Ein darauf basierender Chatbot könnte auf die Frage nach Franziska Giffeys Position mit „Stellvertretende Bürgermeisterin von Berlin“ antworten.
Was der Bot jedoch nicht weiß: Sie hat auch den Posten als Senatorin für Wirtschaft inne.
Diese Information ist nicht explizit Teil des Organigramms der Senatskanzlei und somit dem Bot unbekannt.
Informationen, die eigentlich miteinander in Verbindung stehen sollten, liegen in unterschiedlichen Tabellen.
Um umfassend Auskunft geben zu können, müsste der Bot Zugang zu weiteren Datensätzen haben, in diesem Fall zum maschinenlesbaren Organigramm der Senatsverwaltung für Wirtschaft.
Bei einem Chatbot, der auf eine Vielzahl unterschiedlicher, schwer vorauszusehender Fragen reagieren soll, stößt man hier schnell an Limitierungen.
Die Vision: Das Wissensnetzwerk
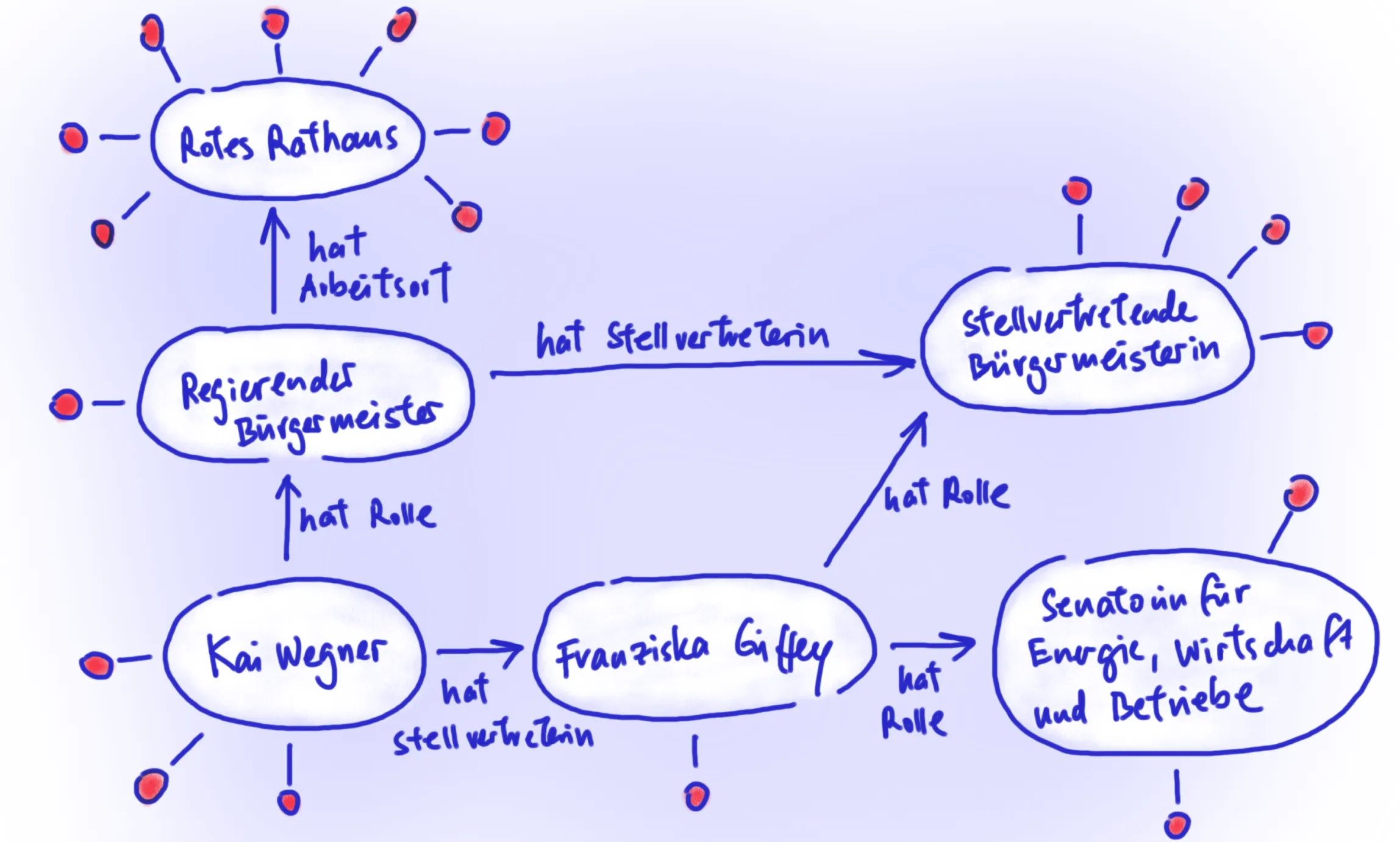
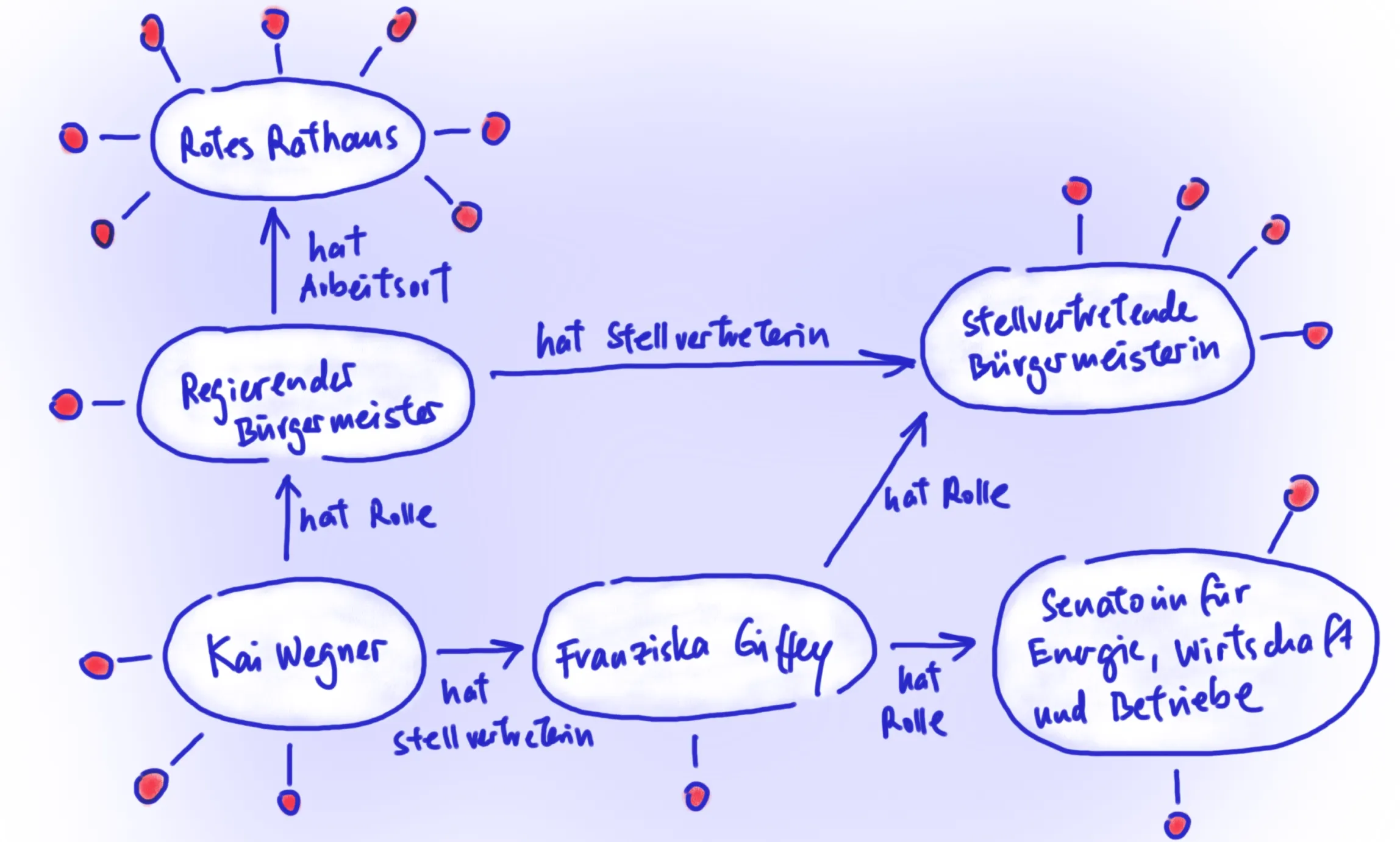
Doch was wäre, wenn alle Informationen, die wir über bestimmte Dinge, Objekte und Prozesse vorliegen haben, automatisch miteinander verknüpft werden könnten?
Wenn ich nach dem Regierenden Bürgermeister frage und der Bot mir nicht nur sagen kann, dass es sich dabei derzeit um Kai Wegner handelt,
sondern dass er seit dem 26.04.23 im Amt ist, dass sein Arbeitsort das Rote Rathaus ist, sein Geburtsort im Bezirk Spandau liegt,
der Bezirk Spandau im Jahr 2023 151.046 EUR für Kindertagesbetreuung ausgegeben hat und so weiter…
Solche Verknüpfung von Daten sind möglich, wenn diese in einem speziellen Format bereitgestellt werden: Linked Open Data!
Das Prinzip ist, dass Inhalte eines Datensatzes durch eindeutige Identifikatoren bezeichnet sind, die es erlauben, unmissverständlich und automatisiert Verbindungen
herzustellen. So kann sich ein Netz an Informationen bilden, auch bezeichnet als „Knowledge Graph“.
Skizze eines Knowledge Graph mit verlinkten Informationen zu den Rollen von Kai Wegner und Franziska Giffey.
An diesem Punkt mag man sich fragen, weshalb all diese Anstrengungen unternommen werden, wenn fortschrittliche Sprachmodelle wie ChatGPT bereits über umfangreiches Wissen verfügen.
Aber auch ChatGPT wurde mit Informationen trainiert, die heute schon wieder veraltet sind.
Wie ein Projekt aus Zürich zeigt, ist ChatGPT aber durchaus in der Lage, aktuelle Information aus Linked Open Data auszulesen und in Kontext zu setzen. Darüber hinaus eröffnet ein gut strukturierter Wissensgraph eine Fülle neuer Fragestellungen und Erkenntnisse. Diese sind nicht nur für spezialisierte digitale Chat-Assistenten wie Bobbi relevant, um stets aktuell zu bleiben, sondern bilden eine wichtige Grundlage für verschiedenste digitale Anwendungen und Prozesse. Sie sind essenziell für die Digitalisierung der Verwaltung, die Beantwortung wissenschaftlicher Fragen oder das Training von Machine-Learning-Modellen.
Inmitten der KI-Revolution wird also deutlich, dass wir für innovative Entwicklungen nicht nur maschinenlesbare Daten bereitstellen müssen. Es ist ebenso entscheidend, dass Informationen aktuell sind, miteinander verknüpft und von Computern semantisch korrekt interpretiert werden können.
Linked Open Data kann helfen Informationen für Programme wie Bobbi zugänglicher zu machen und Daten besser zu nutzen und interpretieren.
Fallstudie
Ein prototypisches Tool zur Erstellung maschinenlesbarer Organigramme
Mit dem Organigramm-Tool arbeiten wir derzeit an einer praxisnahen Fallstudie, um zu lernen, wie wichtige Basis-Daten die Grundlage für einen Knowledge Graph in Berlin legen können.
Wie bereits beschrieben, stellen Organigramme, als Quelle von Informationen über die verschiedenen Verwaltungseinheiten der öffentlichen Verwaltung, eine wichtige Datenquelle dar, die vielfältig Verwendung findet.
Um Organigramme zukünftig in Form von Daten zu veröffentlichen, haben wir als ODIS bereits 2022 ein browserbasiertes Open-Source Organigramm-Tool gebaut, das Mitarbeitende die Organigramme ihrer jeweiligen Häuser bzw. Organisationen in einem offenen, maschinenlesbaren Format (JSON-Datei) erstellen lässt.
Zielstellungen der Fallstudie
Aufgrund ihrer Fülle an Informationen über Aufbau und Struktur der Berliner Verwaltung und ihre hierarchischen Strukturen sind maschinenlesbare Organigramme ein idealer Anwendungsfall für Linked Open Data. Deshalb hat die ODIS das Organigramm-Tool in 2023 so weiterentwickelt, dass die Informationen des Organigramms jetzt auch als Linked Open Data veröffentlicht werden können. Mit dem Tool und dem begleitenden Entwicklungsprozess möchten wir folgende Ziele erreichen:
Praktische Umsetzbarkeit von LOD erforschen: Das Projekt zielt darauf ab, konkret zu erforschen und zu demonstrieren, wie LOD in der Verwaltungspraxis umgesetzt werden kann und welche Herausforderungen dabei auftreten. Es ermöglicht auch anderen Personen und Forschenden mit diesen Daten zu experimentieren und sie mit anderen Datensätzen zu verknüpfen, wodurch neue Möglichkeiten und Erkenntnisse im Bereich LOD entstehen.
Basisdaten als LOD bereitstellen: Durch die Bereitstellung von maschinenlesbaren Organigrammen als LOD trägt ODIS zur Erweiterung des bisher begrenzten LOD-Angebots in Deutschland bei. Linked Open Data wird sein Potential erst entfalten, wenn eine kritische Masse an Wissen entsteht.
Förderung und Entwicklung von LOD-Standards: Mit der neuen Open Data Strategie des Landes wird Linked Open Data als Entwicklungsziel ausgerufen. Wir wollen weitere Akteur:innen im Land ermutigen, Linked Open Data voranzutreiben und ihnen die Möglichkeit geben, sich an ersten Standards zu orientieren, bzw. gemeinsam mit uns Standards weiterzuentwickeln und zu lernen.
Im nächsten Abschnitt erklären wir die wichtigsten Prinzipien von Linked Data und wie wir diese am Beispiel der Organigramme umgesetzt haben.
Prinzipien von Linked Data am Beispiel der Organigramme
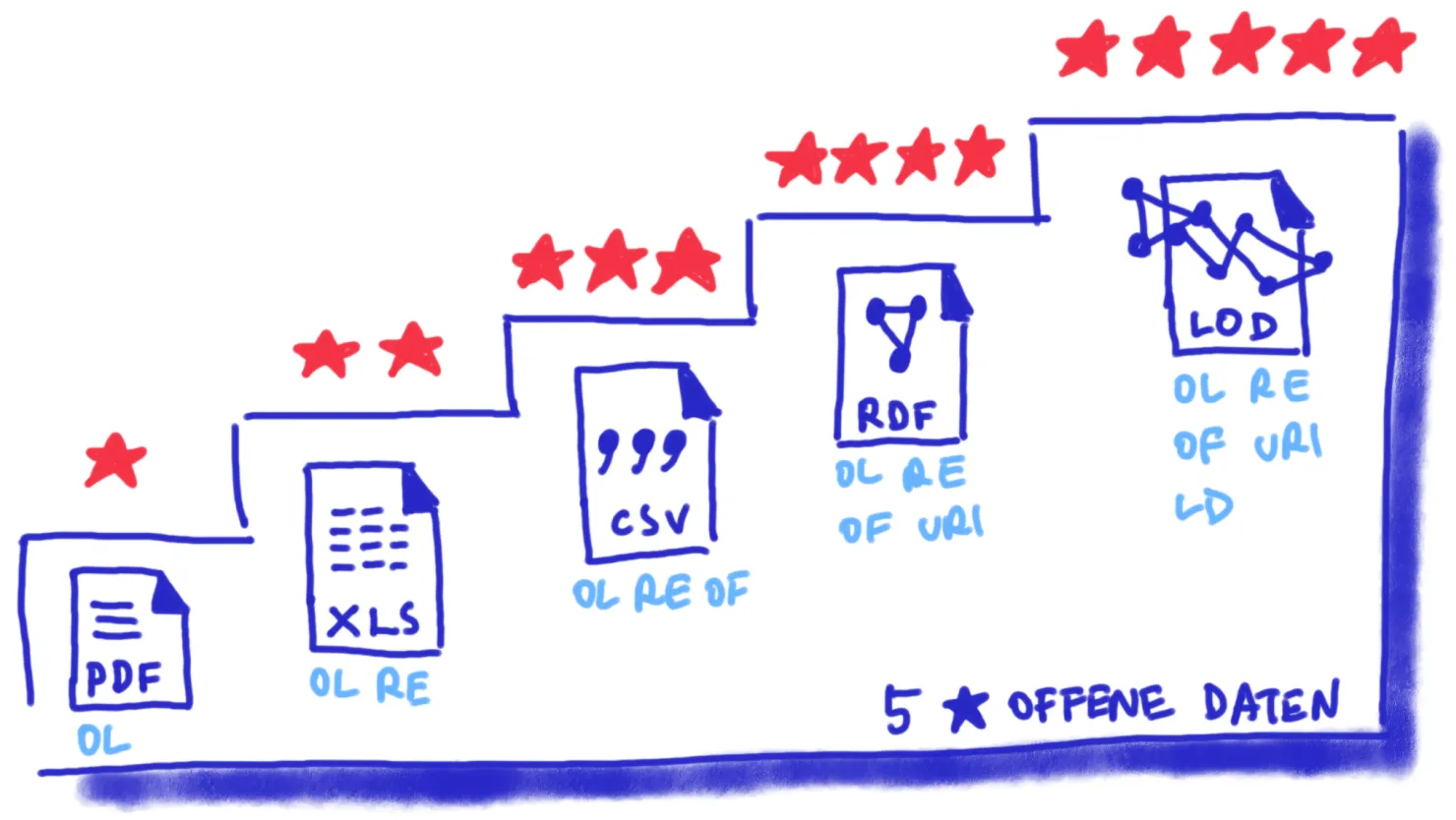
Das Datenqualitätsmodell von Tim Berners-Lee, das von der einfachen Online-Verfügbarkeit (ein Stern) bis hin zur Einbindung in das Web der Daten (fünf Sterne) reicht, bietet eine klare Richtschnur für die Bewertung und Verbesserung der Zugänglichkeit sowie der technischen Nutzbarkeit von Datensätzen.
Datenqualitätsmodell nach Tim Berners-Lee.
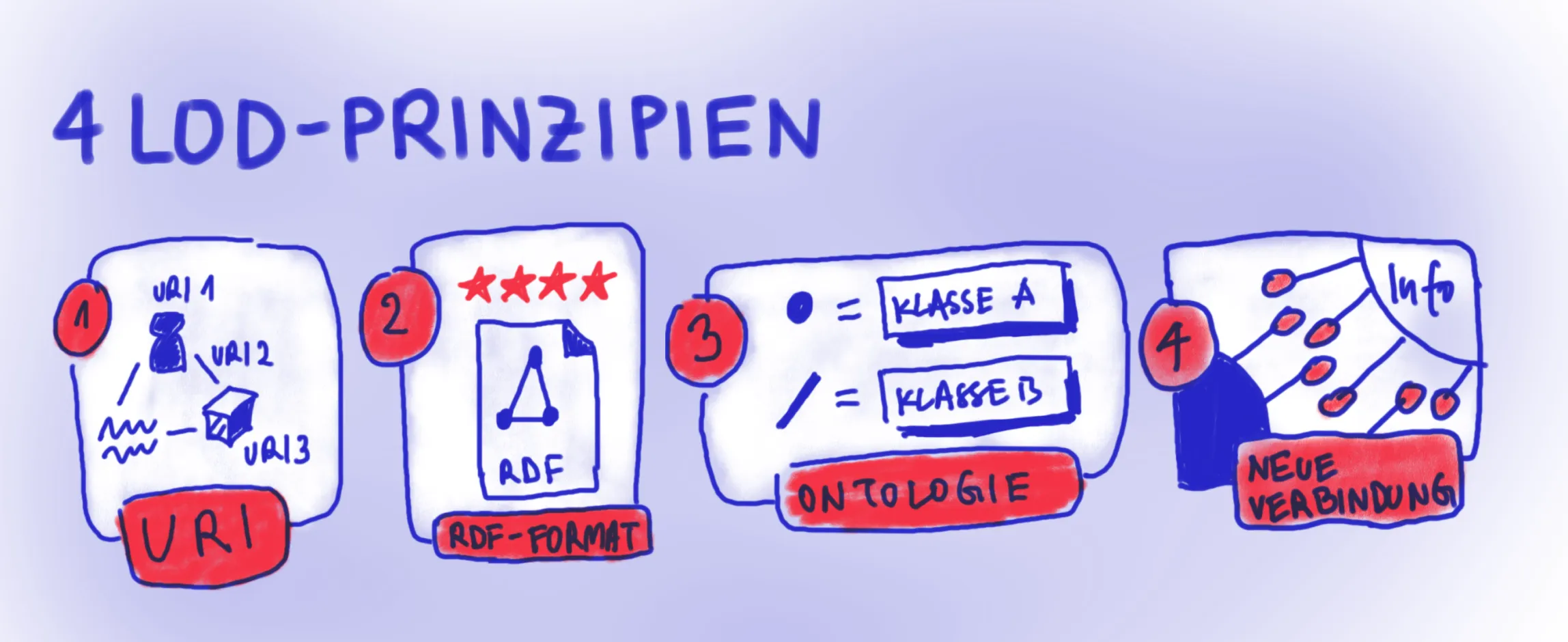
Um die höchste Bewertung von fünf Sternen zu erreichen, müssen die Daten nicht nur maschinenlesbar sein, sondern auch den grundlegenden Prinzipien von Linked Open Data (LOD) entsprechen:
Sie verwenden URIs zum Beschreiben von Gegenständen oder Personen und ihren Eigenschaften sowie Beziehungen zueinander
Sie liegen im RDF-Datenformat vor, das Informationen in einer Art Satzform, inklusive Subjekt, Prädikat und Objekt abbildet
Durch Ontologien, auch Vokabulare genannt, werden mithilfe von Klassen und Eigenschaften festgelegt, welche Beziehungen zwischen den Subjekten und Objekten möglich sind
Durch die Verwendung der Prinzipien lassen sich Verbindungen zwischen Datensätzen herstellen, dafür müssen diese im Netz erreichbar und mit einer speziellen Sprache abgefragt werden können
Die vier LOD-Prinzipien auf einen Blick.
Durch das Organigramm-Tool werden alle vier Prinzipien adressiert. Wie das genau aussieht, wird im Folgenden erklärt.
1. Das Organigramm-Tool als URI-Generator und Editor
Eine grundlegende Voraussetzung für Linked Open Data: Die eindeutige Identifizierung einer Ressource! Anhand von URIs (“Uniform Resource Identifier”) lassen sich abstrakte Ressourcen und Daten im World Wide Web eindeutig identifizieren, wiederfinden und somit auch wiederverwenden.
Ebenso funktionieren URIs im Internet: Sie stellen abstrakte oder konkrete Dinge dar und bilden die Basis für Linked Data. Für die Zugänglichkeit dieser Identifikatoren verwendet Linked Data öffentliche, über HTTP abrufbare URIs. Diese gelten allerdings nicht für ganze Webressourcen wie Webseiten, Artikel, oder PDF-Dateien, sondern beschreiben individuelle Objekte innerhalb von Datensätzen. Im Falle eines Organigramms reicht es zum Beispiel nicht aus, einem gesamten Organigramm einen Link zuzuweisen, wie die fiktive URL organigramm-senatskanzlei-berlin.de. Vielmehr werden den verschiedenen Einzelelementen des Organigramms beim Erstellen bereits URIs zugewiesen.
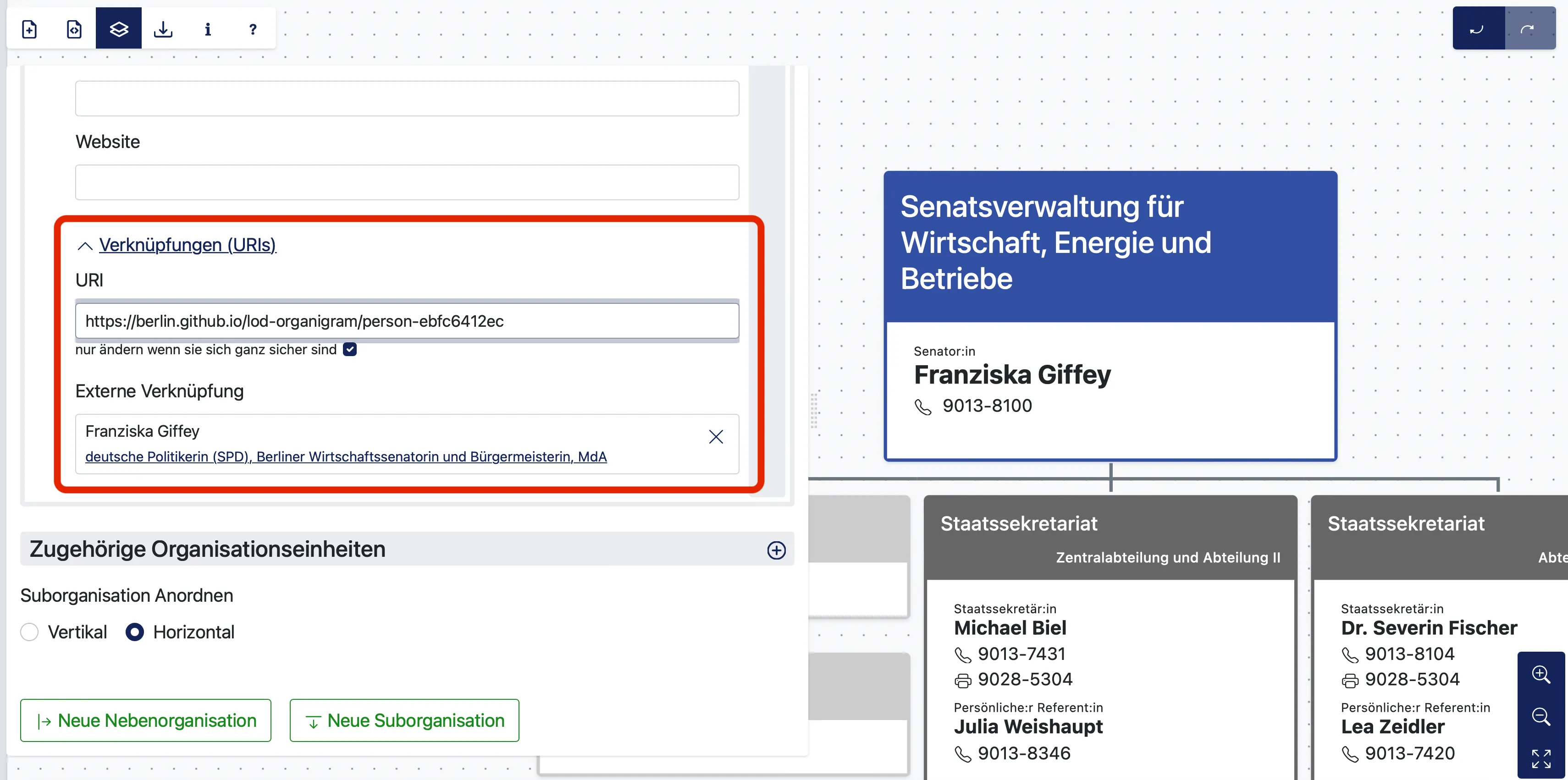
So erhält jede:r Senator:in, Abteilung, Referatsleiter:in oder eine Organisation eine einzigartige URI.
Anlegen einer URI im Organigramm-Tool für Franziska Giffey und Verknüpfung mit der existierenden Wikidata-URI.
Wenn ein Organigramm im Tool angelegt wird, wird für jedes Objekt bzw. Person eine URI automatisch generiert. Die URI’s können aber auch per Hand angelegt und bearbeitet werden. Weiterhin bietet das Tool die Möglichkeit, bereits existierende URI’s von der bestehenden, offenen Datenbank Wikidata zu verknüpfen. Warum das relevant ist, wird später deutlich.
2. Triples im RDF-Format exportieren
Ein weiterer zentraler Aspekt für Linked Data ist die Organisation von Informationen bzw. Aussagen in einer speziellen Struktur, die sich durch eine Dreiteilung auszeichnet. Diese sogenannten Triples bestehen aus einem Subjekt, einem Prädikat und einem Objekt. Das Subjekt repräsentiert die Ressource oder Entität, auf die sich die Aussage bezieht. Dies kann zum Beispiel eine Person sein.
Das Objekt repräsentiert einen Wert oder eine weitere Ressource, die mit dem Subjekt in Beziehung steht. Das könnte ein Objekt zum Beispiel ein Zahlenwert, wie die Höhe des jährlichen Etats sein, aber auch eine weitere Entität, wie zum Beispiel eine Person sein.
Das Objekt wird dann ebenfalls durch eine URI identifiziert. Als Verbindung von Subjekt und Objekt gibt das Prädikat an, welche Art von Beziehung zwischen Subjekt und dem Objekt besteht und welche Informationen sich aus der Verbindung ergeben.
Das Prädikat ist ebenfalls durch eine URI dargestellt; diese werden in einer sogenannten Ontologie, bzw. einem Vokabular festgehalten.
Eine Information die als Triple und codiert in URI’s vorliegt, könnte zum Beispiel so aussehen:
Aussage: Franziska Giffey ist Senatorin für Wirtschaft, Energie und Betriebe.
Da alle in den Datensätzen genannten Entitäten eine einzigartige URI erhalten und diese URIs so gut wie möglich in allen Datensätzen wiederverwendet werden, lassen sich nicht nur Verknüpfungen innerhalb des einzelnen Datensatzes, sondern darüber hinaus Verbindungen zu anderen Datensätzen herstellen, in denen die gleiche URI verwendet wird.
So könnte zum Beispiel die Person Franziska Giffey aus dem Organigramm der Senatskanzlei (in ihrer Rolle als stellvertretende Bürgermeisterin) mit ihrer Rolleninformationen aus dem Organigramm der SenWEB verlinkt werden, wenn in diesem die gleiche URI (person-f60db6579cc) für sie verwendet wurde.
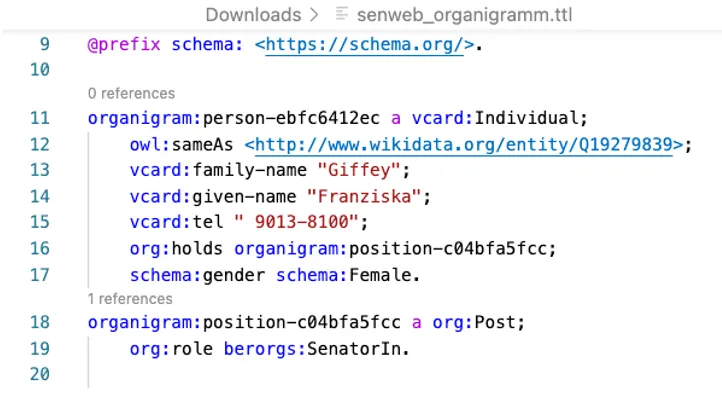
Ein Datensatz besteht aus sehr vielen Triples. Diese werden in einem speziellen Dateiformat, einer RDF-Datei, abgespeichert. Ein im Organigramm-Tool erstelltes Organigramm kann einfach als RDF heruntergeladen werden.
Ausschnitt aus einer RDF-Datei, die Informationen zu Franziska Giffey als Senatorin enthält.
3. Eine Ontologie speziell für Berliner Organigramme
Eine weitere Voraussetzung für Linked Data ist die Verwendung von standardisierten Ontologien, also eine Art spezialisierter Vokabulare. Sie bieten eine formalisierte Darstellung von Begriffen und deren Beziehungen in einem bestimmten Wissensbereich.
Ontologien können als Schemas verstanden werden, die Struktur und Bedeutung von Daten in einem bestimmten Kontext festlegen. Sie ermöglichen, dass Computerprogramme die Bedeutung von Daten “verstehen”.
Ein Beispiel für eine existierende Ontologie die häufig zur Beschreibung von Personen verwendet wird, heißt vCard.
Ein Webeintrag beschreibt, wie die Ontologie benutzt wird und bietet einen Überblick über ihre Begriffe, also Beziehungen und Informationen, die mit ihrem Vokabular abgebildet werden können. Bei vCard sind das zum Beispiel die Namen, Anschrift und Kontaktmöglichkeiten einer jeweiligen Person. Die Ontologie stellt somit URIs bereit, die benötigt werden, um Informationen als Triples auszudrücken.
Diesem Prinzip folgend, bedient sich das Organigramm-Tool sowohl bestehender Vokabulare als auch eines von uns speziell für Berlin verfassten.
Um die Beziehungen verschiedener Abteilungen und Mitarbeitenden akkurat abzubilden, entwickelte die ODIS für die Organigramme auch ein eigenes Vokabular.
Unser Webeintrag in Form eines GitHub-Repositories definiert Berlin-spezifische Einrichtungen und Positionen und stellt die URIs dafür bereit, zum Beispiel für die Rolle “SenatorIn” (https://berlin.github.io/lod-vocabulary/berorgs/SenatorIn).
4. Wissen unbegrenzt verlinken
Das Organigramm-Tool ermöglicht es also Daten im RDF-Format unter Verwendung von Standards zu erstellen und herunterzuladen. Um zu echten Linked Open Data zu kommen, gilt es noch einen Schritt weiterzugehen, nämlich die Daten im Internet verfügbar zu machen, sodass sie abgefragt und mit externen Daten verlinkt werden können.
Dafür ist eine besondere Art von Datenbank erforderlich, ein sogenannter Triple Store. Der Triple Store ermöglicht effiziente Verwaltung und Abfrage von Linked Data, indem er die Triples und somit die Beziehungen zwischen verschiedenen Datenpunkten speichert.
Um die Informationen eines Triple Stores abzufragen, gibt es die Abfragesprache SPARQL.
Das Ergebnis einer Abfrage kann in Form einer Tabelle ausgegeben werden, die eine Reihe von Triples widerspiegelt, die Informationen zu dieser bestimmten Person abbildet.
Eine Abfrage, die uns eine Liste von allen Senator:innen von Berlin zurückgeben soll, könnte beispielsweise so aussehen:
Die Abfrage sucht nach Entitäten (?person) und ruft die gespeicherten Informationen zu Vornamen, Nachnamen, Position und die Wikidata-URI ab. Dann filtert sie die Personen nach der in unserer Ontologie definierten Position “SenatorIn”.
Im zweiten Teil der Abfrage zeigt sich das eigentliche Potential von Linked Data. Hier wird eine Verlinkung zur Wikidata-Datenbank hergestellt und ein Bild (?image) der jeweiligen Senator:innen abgerufen.
Beispiel einer SPARQL-Abfrage die die Organigramm-Daten mit Informationen von Wikidata verknüpft.
Sprachmodelle wie ChatGPT (das Modell ist eig. GPT-4) könnten eine zusätzliche Rolle bei der Zugänglichkeit der Daten spielen. Sie sind in der Lage, Code zu schreiben und zu interpretieren, was bedeutet, dass sie natürliche Sprache in SPARQL-Abfragen umwandeln und die Ergebnisse verarbeiten können. Dies erweitert die Zugänglichkeit und Nutzbarkeit von Linked Open Data erheblich, da Benutzer nicht mehr direkt mit komplexen Abfragesprachen interagieren müssen. Ein praktisches Beispiel hierfür ist das schon erwähnte ZüriLinkedGPT, dass den Linked Data Triple Store der Stadt Zürich in natürlicher Sprache abfragbar macht.
Weiterhin können sie auch helfen, die neu generierten Daten zu verarbeiten, zum Beispiel für die schnelle Erstellung von Anwendungen oder Analysen, wie der folgende Screencast zeigt.
Beispiel von der Nutzung eines Sprachmodells um mit den neuen, durch die Verlinkung erstellten Datensatzes weiterzuarbeiten. Es wird eine Karte mit den Geburtsorten der Senatoren erstellt.
Zusammenfassung und Ausblick
Wie geht’s weiter
Mit dieser Fallstudie wollten wir an einem Praxisbeispiel die Potentiale und Herausforderungen bei der Umsetzung von Linked Open Data in Berlin erkunden.
Das Organigramm-Tool hat dabei geholfen Umsetzungskompetenzen aufzubauen, soll aber auch als Pilotprojekt fungieren.
Bisher wurden für die Fallstudie mit dem prototypischen Tool Organigramme für vier verschiedene Senatsverwaltungen erstellt und im Triple Store für Test- und Demonstrationszwecke zur Verfügung gestellt.
Ziel ist es, für und gemeinsam mit allen Senatsverwaltungen Linked Open Data Organigramme bereitzustellen. Dafür wird im nächsten Schritt die Umsetzung in den Verwaltungen angestoßen. Weiterhin soll die Ontologie dabei iterativ verbessert und ausgebaut werden.
Darüber hinaus können natürlich weitere Behörden in und außerhalb Berlins das Tool nutzen.
Letztendlich handelt es sich um ein lernendes Projekt, das helfen soll, die Themen Datenmanagement, -infrastruktur und -verfügbarkeit voranzubringen!
Fokussetzung
Ursprünglich sollte das Organigramm-Tool auch dazu verwendet werden, die PDF-Organigramme ebenfalls zu ersetzen und zu standardisieren (das Tool ermöglicht einen PDF-Export).
Es hat sich aber in Tests und Feedbackschleifen mit zuständigen Personen der Senatsverwaltungen gezeigt, dass die Anforderungen an die grafische Darstellung der Organigramme sich kaum mit den Anforderungen an eine maschinenlesbare, strukturierte Datei vereinbaren lässt.
Die Übertragung der vielen Sonderfälle und darstellerischen Feinheiten, die derzeit mit Tools wie Microsoft PowerPoint umgesetzt werden, lässt sich zum jetzigen Zeitpunkt nicht vollständig technisch umsetzen.
Das Organigramm-Tool verfolgt daher in erster Linie den Zweck, maschinenlesbare Datensätze zu erstellen und regelmäßig zu aktualisieren.
Weitere Linked Data Projekte
Damit perspektivisch eine kritische Masse an Datensätzen verknüpft werden und darüber neue Einsichten gewonnen und innovative Lösungen für komplexe Probleme entwickelt werden können, bedarf es außerdem eines größer werdenden Pools an Linked Open Data.
Bisher sind erst wenige verlinkte offene Daten über Berlin verfügbar. Einer davon sind die lebensweltlich orientierten Räume (LOR) Berlins, geografische Untereinheiten, die als Grundlage für Planung, Prognose und Beobachtung demografischer und sozialer Entwicklungen dienen. Über GitHub können sich Nutzer:innen jegliche Unterteilungen anzeigen lassen, von einer Übersicht aller Bezirke zur kleinsten Untereinheit, wie beispielsweise die “Zwinglistraße” im Bezirk Mitte (Planungsraum 01022105).
Weiterhin als Linked Data verfügbar sind die Bevölkerungszahlen.
Weiterhin hat sich im Rahmen des Vierten Nationalen Aktionsplanes die Berliner Senatsverwaltung für Finanzen verpflichtet, den bereits seit vielen Jahren als offene Daten veröffentlichen Doppelhaushalt, als Linked Data im RDF-Format zu veröffentlichen.
Mit tausenden von Ausgabe- und Einnahmetiteln, also Informationen zur Höhe und Zweck von Einnahmen und Ausgaben, enthält der Haushalt wichtige Informationen mit örtlichem und politischem Bezug.
Durch die standardisierte Bereitstellung von Daten im RDF-Format könnte ebenfalls eine Verbindung zwischen maschinenlesbaren Organigrammen, den LOR und den Haushaltsdaten hergestellt werden. Ohne mühsames manuelles Zusammentragen von Daten können so Erkenntnisse über die Berliner Verwaltung, ihre Organisation und ihre Finanzen gewonnen werden.
Die Umsetzung ist für 2024 geplant und soll auf unserer Ontologie aufbauen, damit eine einheitliche “Sprache” gesprochen wird und Daten letztendlich verlinkt werden können.
Sparring-Partner gesucht!
Bei Fragen oder Feedback zur Fallstudie oder zum Organigramm-Tool, freuen wir uns über einen Austausch, genauso wie über Ideen für mögliche Linked Open Data Projekte. Wir wollen den Weg zu den 5*Sternen im Austausch mit der Community und Verwaltung gehen und laden dazu ein, gemeinsam neue Ansätze und Pfade zu erkunden und Wissensschätze zu sammeln.
Wir sind mindestens so gespannt wie Chatbot Bobbi auf die weiteren Entwicklungen im Land in Hinblick auf Linked Data und Open Data.
In Organigrammen steckt eine Menge Informationen und viele Anwendungspotenziale, wenn es uns gelingt ihre Logiken zu verstehen und einheitliche Standards zu entwickeln. Wir haben versucht den Organigramm-Dschungel zu durchdringen.
Am Beispiel der Organigramme arbeiten wir derzeit an einer praxisnahen Fallstudie, um zu lernen, wie mit wichtigen Basis-Informationen die Grundlage für Linked Open Data in Berlin gelegt werden kann.