Wer liest was? Stadtteilbibliothek Pankow veröffentlicht ersten offenen Datensatz zu Bibliotheksdaten in Berlin
In der Zusammenarbeit zwischen der Stadtteilbibliothek Pankow und ODIS konnte ein relevanter Datensatz auf dem Open Data Portal veröffentlicht werden. Dieser enthält Informationen zu allen über 1,5 Millionen getätigten Ausleihen und Verlängerungen in Pankower Bibliotheken im Jahr 2022. Wir verraten, welche Herausforderungen wir vor der Veröffentlichung meisterten und geben Einblick in den Datenschatz.
Die Leitung der Janusz-Korczak-Bibliothek in Pankow entschied sich im vergangenen Jahr, Bibliotheksdaten als offene Daten bereitzustellen. Ziel der Bibliotheksleitung ist es, mithilfe der offenen Daten gezieltere Analysen durchführen zu können, um beispielsweise das Nutzungsverhalten oder die Reichweite der einzelnen Bibliotheksstandorte auszuwerten. Wir waren natürlich neugierig darauf, welche spannenden Informationen in den Daten zu finden sind und unterstützten Tobias Weiß, den Leiter der Bibliothek, gemeinsam mit Karsten Gartner, dem Open-Data-Beauftragten des Bezirks, gerne bei der Aufbereitung, Anonymisierung und Bereitstellung der Daten.
Der Datensatz ist seit Februar 2022 mit den nötigen Schlüsseltabellen und der Dokumentation im Berliner Open Data Portal abrufbar. Wie der Weg bis hin zur Veröffentlichung war, möchten wir in diesem Blogbeitrag aufzeigen.
Über das zentrale Verbundservicezentrum (VSZ) der Zentral- und Landesbibliothek (ZLB) erhält die Pankower Stadtteilbibliothek Statistiken über die Medienausleihungen im Bezirk. Bei der ersten gemeinsamen Sichtung des Datensatzes zur Ausleihstatistik vor Ort kristallisierten sich drei zentrale Herausforderungen heraus:
Wie können die Daten so verändert werden, dass keine Rückschlüsse auf individuelle Bibliotheksnutzer:innen gezogen werden können, ohne gleichzeitig einen allzu hohen Informationsverlust zu riskieren?
Wie kann der mit Fachbegriffen und Codes gespickte Datensatz so aufgewertet werden, dass die Informationen verständlich und nutzbar werden?
Wie kann eine erfolgreiche Veröffentlichung im Berliner Open Data Portal und eine jährliche Aktualisierung realisiert werden?
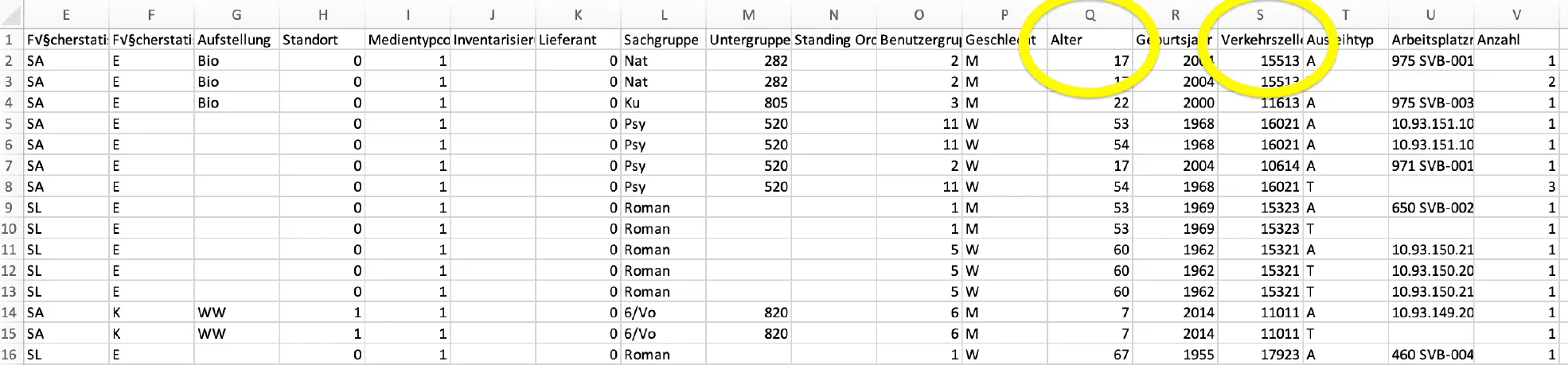
Der Rohdatensatz enthält personenbezogene Daten, zum Beispiel Alter und Wohnort auf Ebene der Teilverkehrszellen
Der Schutz persönlicher Daten ist selbstverständlich äußerst wichtig, doch er muss nicht automatisch gegen eine Veröffentlichung der Daten sprechen. Durch ein Anonymisierungsverfahren können die Daten so verändert werden, dass Rückschlüsse auf Individuen gar nicht mehr oder zumindest nur noch mit unverhältnismäßig hohem Aufwand möglich sind.
Im Bibliotheksdatensatz sind die Informationen zu Alter, Geschlecht, Geburtsjahr, Benutzergruppe und Wohnort sensible, personenbezogene Daten. Da es sich bei den Angaben zum Wohnort um die kleinräumliche Einheit der Teilverkehrszellen (TVZ) handelt, in der zum Teil weniger als 100 Menschen gemeldet sind, ist diese Information besonders kritisch.
Folgende Schritte der Datenverarbeitung haben wir zur Anonymisierung durchgeführt:
Ableiten des Bezirks auf Basis der TVZ und Löschen der Angabe zur TVZ, wenn dort zu wenige Menschen gemeldet sind (auf Basis eines Datensatzes des Amt für Statistik Berlin Brandenburg)
Generalisierung der Angaben zu Alter und Geburtsjahr in Altersgruppen
Prüfen, dass es genügend Einträge zu allen Merkmalskombinationen der personenbezogenen Spalten gibt und ggf. Löschen von Informationen zu TVZ, Geschlecht, Altersgruppe oder Benutzergruppe, sodass es genügend Einträge zu allen Merkmalskombinationen gibt. Dies folgt dem Prinzip der k-Anonymität, nach dem mindestens eine bestimmte Anzahl von Einträgen im Datensatz vorhanden sein muss, die eine bestimmte Merkmalskombination teilen. Dadurch ist jede Person Teil einer größeren Gruppe und Einträge können nicht mehr einer einzelnen Person zugeordnet werden.
Generalisierung der exakten Zeitstempel zu jeder Ausleihe in Monatsangaben
Durch Iterationen beim Löschen von Werten konnten wir dafür sorgen, dass nur so viele Informationen wie nötig aus dem Datensatz entfernt und auf NaN gesetzt wurden. Die einzelnen Anonymisierungsschritten haben wir in Form eines Python Skripts automatisert. Unser Vorgehen wurde vom bezirklichen Datenschutzbeauftragten positiv bewertet und der Datensatz zur Veröffentlichung freigegeben.
Weiter werteten wir den Datensatz auf, um die Nutzung der Daten zu erleichtern. Redundante Spalten wurden gelöscht und Codes z.B. für Mediennummern, Benutzergruppen oder Fächerstatistiken übersetzt. Gleichzeitig wollten wir den Datensatz bzw. die Beschreibung der Daten nur dort verändern, wo eine nachvollziehbare Übersetzung Sinn macht. So blieben zum Beispiel die Sigelnummern im Datensatz enthalten, die jeweils für einen Bibliotheksstandort stehen. Dafür stellt die Stadtteilbibliothek Pankow eine Schlüsseltabelle auf dem Open Data Portal zum Download zur Verfügung.
Für die Sachgruppen und Untergruppen, die das Genre der Medien beschreiben, ist ebenfalls eine separate Schlüsseltabelle im Open Data Portal abrufbar. Die Sachgruppen folgen der Systematik für Bibliotheken (SfB) und tauchen meist als Kürzel im Datensatz auf. Bisher gab es keine maschinenlesbare Übersicht der Sachgruppen, weshalb wir mithilfe eines Scraping-Skripts eine Schlüsseltabelle als CSV erstellt haben.
Mit über 1,5 Mio. Einträgen und einer Dateigröße von rund 300 MB ist der Datensatz größer als die üblichen Datensätze, die auf dem Open Data Portal veröffentlicht werden. So liegt das Upload-Maximum bei Imperia bei 30 MB. Dank einer Schul-Cloud des Bezirks Pankow konnte der Open-Data-Beauftragte Karsten Gartner den Datensatz hochladen und über die Datenrubrik auf dem Open Data Portal bereitstellen.
Für die geplante, jährliche Veröffentlichung des Datensatzes kann die Stadtteilbibliothek den neuen Datensatz durch das von uns entwickelte Skript jederzeit erneut automatisiert anonymisieren und aufbereiten.
Im Open Data Portal ist neben dem Datensatz und den Schlüsseltabellen auch eine Dokumentation bereitgestellt, die die einzelnen Spalten und Kategorien erklärt.
Auszug aus der Dokumentation, bereitgestellt durch die Stadtteilbibliothek Pankow und veröffentlicht im Open Data Portal
Welche Erkenntnisse lassen sich nun aus den Daten gewinnen? Jeder Eintrag stellt einen Ausleih- oder Verlängerungsvorgang dar – sowohl erfolgreiche als auch fehlgeschlagene. Darin enthalten sind vielfältige Informationen über den Ausleihvorgang, das Medium selbst oder über die Bibliotheksnutzer:innen. So lässt sich durch Abfragen des Datensatzes schnell herausfinden, welche Sachbücher bei Kinder- und Jugendlichen gefragt sind, welche Bibliotheksstandorte am häufigsten genutzt oder wann Medien über den Jahresverlauf gesehen am meisten nachgefragt werden.
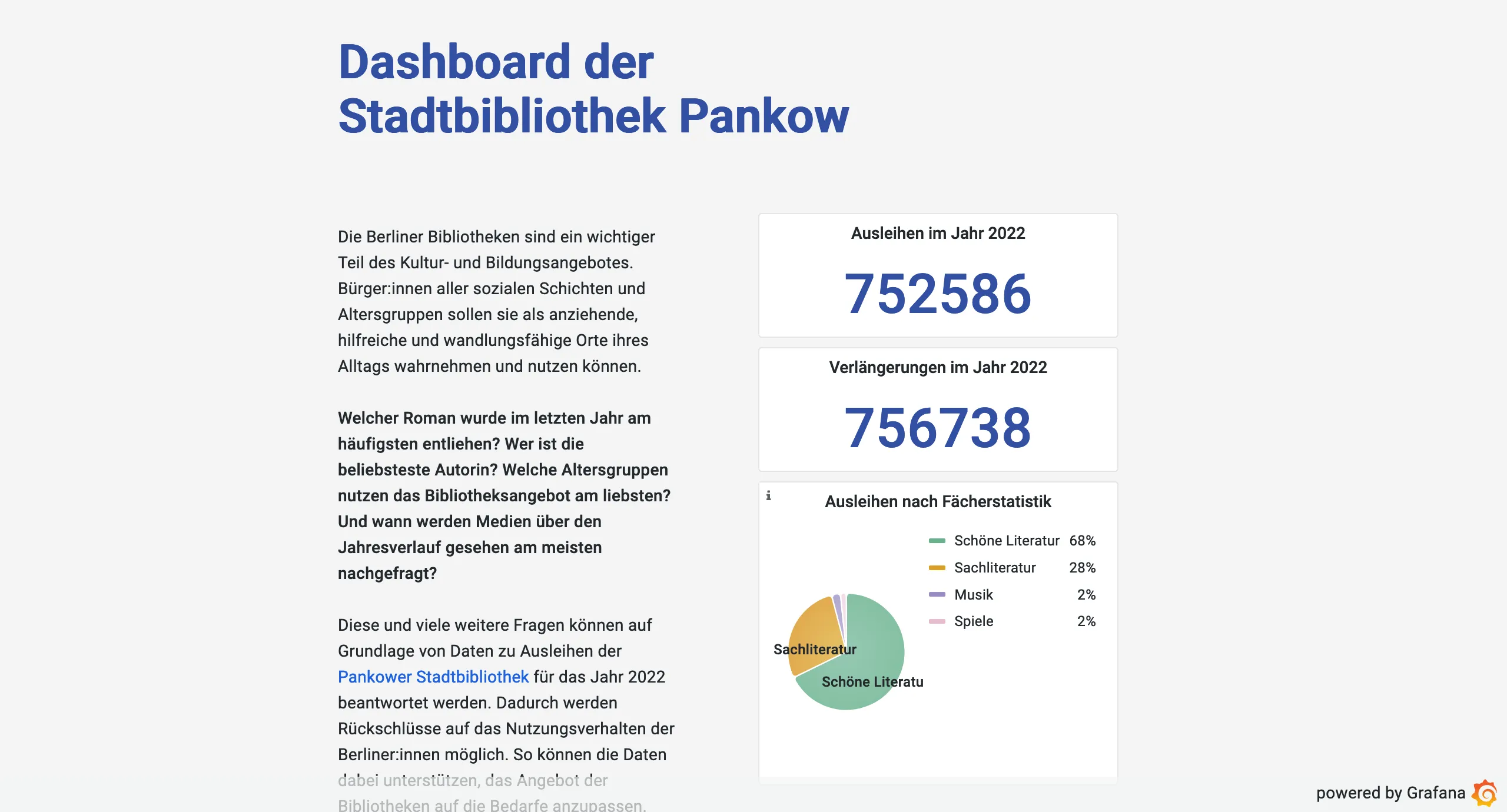
Ein paar dieser Analysen haben wir im Rahmen eines Dashboards visualisiert. Wir wünschen viel Vergnügen beim Stöbern durch die digitale Stadtteilbibliothek Pankow!
Das Dashboard zeigt verschiedene Analysen, zum Beispiel die Anzahl der Gesamtausleihen oder die Fächerstatistik
Welche Medien waren 2023 im Trend? Wir haben das Bibliotheksdashboard der Stadtteilbibliothek Pankow mit neuesten offenen Daten aus dem vergangenen Jahr gefüttert und erneut relevante Aussagen über das Nutzungsverhalten von Besucher:innen visualisiert.
ODIS lud Verwaltungsmitarbeitende zur Geodatenschulung. Mit dem neu erworbenen Wissen in QGIS können nun räumliche Auswertungen erstellt und neue Erkenntnisse rund um die Nutzung der Bibliotheken erlangt werden, etwa zur Erreichbarkeit der Standorte und der Anpassung des Angebots an die Nutzenden.