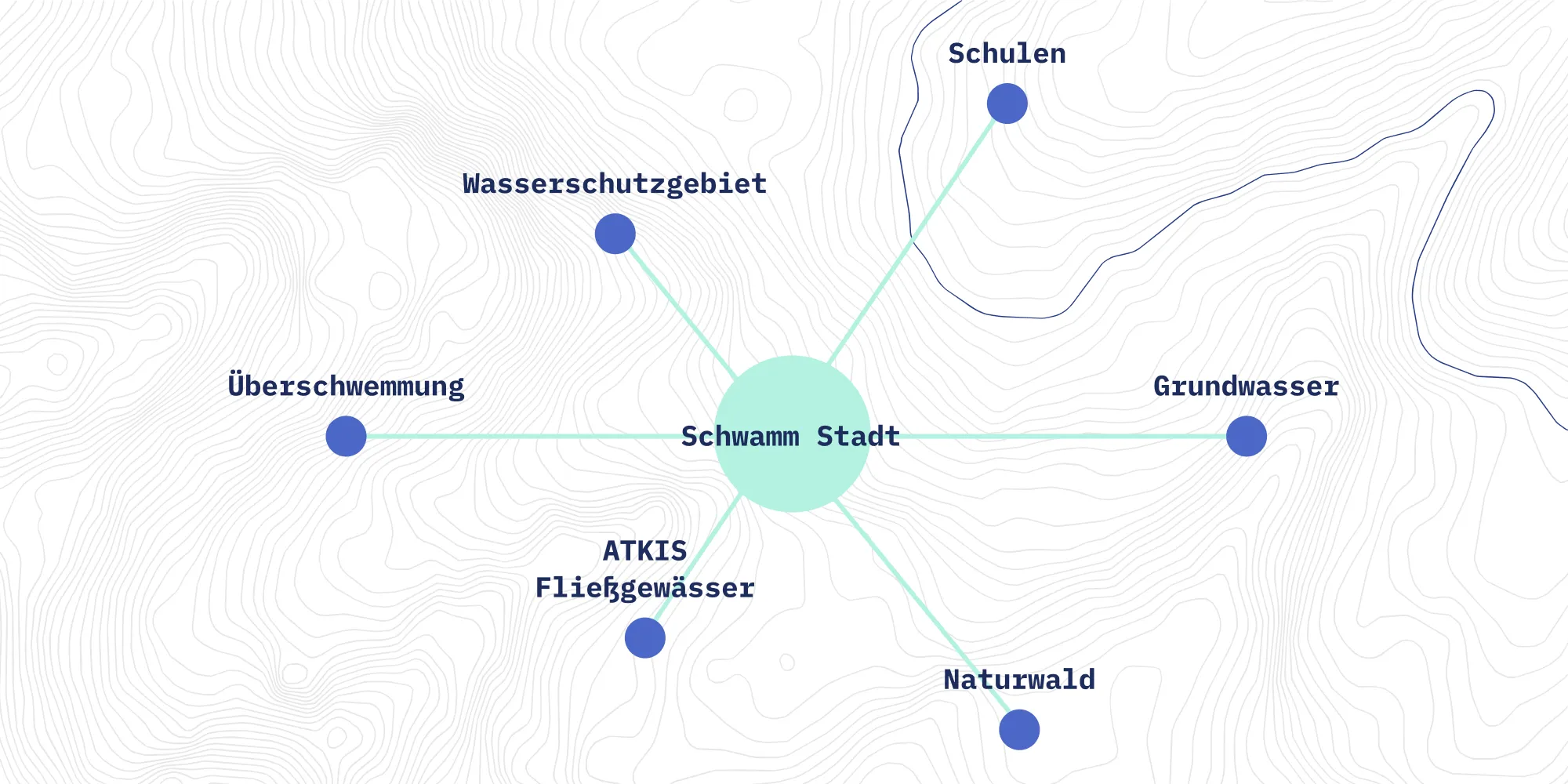
Hintergrund
Geodaten können für städtische Projekte von großer Bedeutung sein. Sie unterstützen etwa bei der Planung städtischer Infrastruktur wie Radwegnetzen, Spielplätzen oder Trinkbrunnen oder erlauben die Überwachung von Klima- und Umweltschutzmaßnahmen. Das Land Berlin verfügt dabei über einen enormen Schatz an Geodaten.
Im Zuge der allgemeinen Diskussion um die Nutzung von KI-Sprachmodellen, dem sogenannten “Large Language Model” (LLM), geht der GeoExplorer als Proof of Concept der Frage nach, wie KI in Verbindung mit offenen Geodaten eingesetzt werden kann. Kann KI uns helfen Daten besser zu finden, zu verstehen, ihre Relevanz für ein Vorhaben zu bewerten und vielleicht sogar ganz neue Ideen zu generieren?
Der GeoExplorer stellt dabei keine Alternative zur Geodatensuche der Senatsverwaltung für Stadtentwicklung, Bauen und Wohnen (SBW) oder zum Berliner Open Data Portal dar, sondern soll eine Möglichkeit für Anwender:innen bieten, die sich bisher wenig mit Geodaten aus der Berliner Verwaltung auskennen.
GeoExplorer: Mehr als eine reine Geodatensuche
Mit dem GeoExplorer ist es möglich, das Geodatenangebot des Landes Berlin in einem Freifeld oder alternativ mit vorgegebenen Suchvorschlägen zu explorieren. Entsprechend der Suchanfrage liefert der GeoExplorer eine nach Relevanz gegliederte Ergebnisliste, die von dem dahinterliegenden KI-Sprachmodell die Relevanz der Datensätze zu der Suchanfrage abbildet.
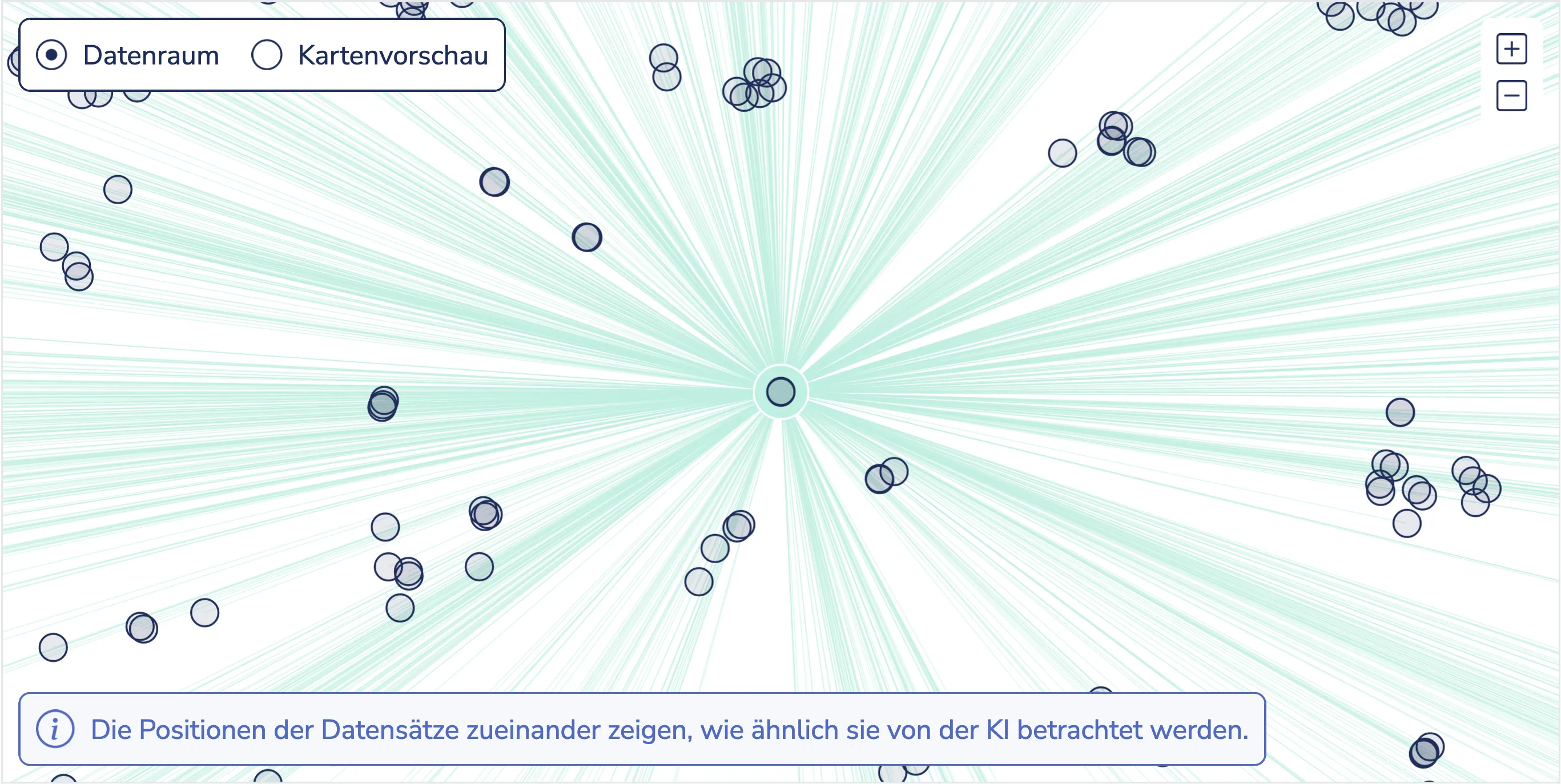
Mit einem Klick auf “Mehr Infos” eröffnen sich detaillierte Informationen und Zugänge zum Geodatensatz.
- Weiterführender Link zur ursprünglichen Metadatenquelle
- GeoJSON-Downloadmöglichkeit des Datensatzes in einer weit verbreiteten Projektion (WGS84)
- Link zum WFS- bzw. WMS-Dienst zur Weiterverarbeitung zum Beispiel in einem Geoinformationssystem (GIS)
- KI-gestützte Beschreibung des Datensatzes, wie Entschlüsselung der Attribute oder Einordnung der Relevanz des Datensatzes
- Kartenvorschau des Datensatzes zur ersten Einordnung der räumlichen Ausprägung der Daten
- Übersicht über weitere möglicherweise relevante Datensätze im sogenannten Datenraum durch Anzeige von Nähe und Distanz der Datensätze zueinander
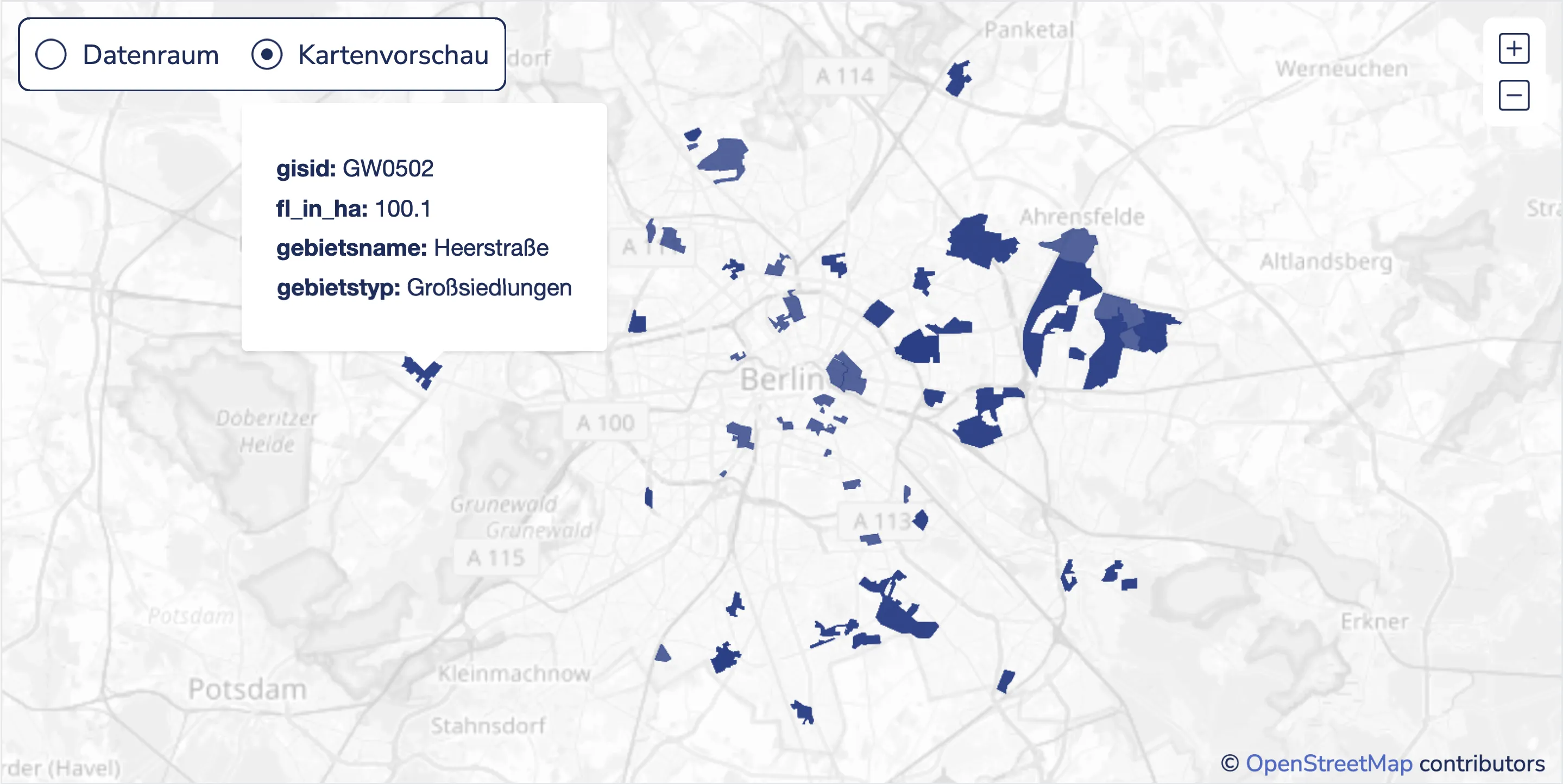
Datengrundlage und Methodik
Für jeden Datensatz wurden sogenannte Metadaten aus dem Berliner Open Data Portal und Berlins Geodatenportal automatisiert gescraped (gesammelt). Die offenen Geodaten liegen in der Berliner Geodateninfrastruktur, die von der Senatsverwaltung für Stadtentwicklung, Bauen und Wohnen (SenSBW) betrieben wird. Als Metadaten werden Daten bezeichnet, die einen Datensatz beschreiben, z.B. die Attribute, die ein Datensatz hat, oder der von einem Menschen geschriebene Beschreibungstext. Das Script zum Scrapen der Daten findet sich in unserem Github-Repository.
Anschließend wurde für jeden einzelnen Metadatensatz ein sogenanntes Embedding erstellt und in eine Datenbank geschrieben. Jedes Embedding enthält einen speziellen Vektor, der auf dem Inhalt der Metadaten basiert. Dieser Vektor ist wie eine Art multidimensionale Koordinate, die den Inhalt der Metadaten in der Logik der KI verortet. Beispiel: Die möglichen Vektoren für die Begriffe “Hund” und “Katze” liegen näher beieinander als der Begriff “Auto”, bei dem es sich nicht um die gemeinsame Kategorie “Tier” handelt.
Bei der Suchanfrage wird daraufhin ein Vektor erstellt und mit den vorhandenen Vektoren in der Datenbank verglichen. Falls die Vektoren eine gewisse Nähe zueinander aufweisen, werden die jeweiligen Embeddings im Suchergebnis angezeigt. Der GeoExplorer wird derzeit (noch) unregelmäßig aktualisiert.
Die verarbeiteten Daten und die Skripte zur Datenprozessierung sind in diesem GitHub-Repository zu finden.
Hinweis zur Nutzung von KI
Ein LLM ist ein hochentwickeltes KI-gestütztes System, das speziell dafür konzipiert ist, menschliche Sprache in ihrer Komplexität zu erfassen und zu simulieren. Die Technologie basiert auf der Analyse und Verarbeitung großer Mengen Textdaten, die aus einer Vielzahl von Quellen wie Büchern, Artikeln und Internetinhalten stammen. Durch maschinelles Lernen und komplexe Algorithmen entwickelt das Modell die Fähigkeit, Texte zu verstehen, zu generieren und auf menschenähnliche Weise zu interagieren. Es kann Aufgaben wie das Beantworten von Fragen, das Übersetzen von Sprachen und das Erstellen von Texten verschiedenster Art übernehmen. Trotz ihrer beeindruckenden Leistungsfähigkeit sind LLMs nicht fehlerfrei und ihre Interpretationen können gelegentlich vom menschlichen Verständnis abweichen. Sie repräsentieren den aktuellen Stand der KI-Entwicklung im Bereich der natürlichen Sprachverarbeitung, bleiben aber ein Werkzeug, dessen Ergebnisse stets kritisch hinterfragt und kontextualisiert werden sollten.
Hinsichtlich des Datenschutzes ist zu beachten, dass der GeoExplorer das KI-Modell von Mistral verwendet, das heißt Anfragen werden an Mistral weitergeleitet, die das Unternehmen nach eigenen Datenschutzrichtlinien verarbeitet. Eine Speicherung der Anfragen durch uns erfolgt nicht. Darüber hinaus fallen bei jeder Abfrage geringfügige Kosten aus Mitteln der öffentlichen Hand für die Nutzung von Mistral an und jede Anfrage ist mit einem erhöhten Stromverbrauch im Vergleich zu herkömmlichen Suchmaschinen verbunden.