MCP-Server im Praxistest mit Berlins offenen Daten
Generative KI hat das Potenzial, den Zugang zu offenen Daten zu vereinfachen. Wir haben zwei MCP-Server entwickelt, damit Berlins offene Daten mithilfe von KI-gestützten Schnittstellen noch besser gefunden, analysiert und visualisiert werden können. In diesem Praxisartikel erklären wir, wie MCP-Server funktionieren und was wir bei der Entwicklung gelernt haben.

Einleitung
Vom Suchen zum Fragen
Konversationelle KI verändert derzeit grundlegend, wie Menschen Informationen suchen, analysieren und nutzen. Statt klassische Webrecherchen durchzuführen, antworten Sprachmodelle direkt auf Fragen wie:
„Wo werden in Berlin die meisten Fahrräder gestohlen?“
„Welcher Bezirk hat im Schnitt die höchsten Mieten?“
„Wo finde ich den nächsten Trinkbrunnen?“
Doch woher stammen die Informationen, auf denen die Antworten der LLMs basieren? Ein Teil des Wissens steckt bereits im trainierten Modell. Inzwischen greifen moderne KI-Anwendungen wie ChatGPT oder Claude zusätzlich auf externe Quellen wie Suchmaschinen, Datenbanken oder spezialisierte Dienste zu. Für Nutzende bleibt dabei oft unklar, welche Informationen aus welchen Quellen tatsächlich verwendet werden und wie die KI zu ihren Antworten gelangt. Diese fehlende Transparenz wird besonders dann zum roten Tuch für Anwender:innen, wenn Konversationen mit dem LLM zwingend auf vertrauenswürdigen und aktuellen Daten basieren sollen.
KI-gestützter Zugriff auf Open Data
Abhilfe könnte das Model Context Protocol (MCP) schaffen. MCP ist im Grunde eine Art Schnittstelle, über die Sprachmodelle mit externen Datenquellen und Tools verbunden werden können. Als Open Data Informationsstelle Berlin sind wir überzeugt, dass konversationelle KI das große Potenzial hat, die Verwendung offener Daten zum Positiven zu verändern. Wir haben deshalb zwei MCP-Server für Berlin entwickelt, aufgesetzt und getestet. Unser Ziel war es herauszufinden, was passiert, wenn dieser Ansatz auf Berlins reale offene Verwaltungsdaten trifft und ihn für Interessierte zur freien Nutzung zur Verfügung zu stellen.
In diesem Beitrag erklären wir:
- Was ist MCP und wie funktioniert die Verbindung von LLMs zu Datenquellen?
- Wie lassen sich die von uns entwickelten MCP-Server nutzen und was sind Beispiel-Prompts?
- Wie funktionieren unsere MCP-Server, zum einen für die Suche und Exploration von Daten im Berliner Datenportal und zum anderen für die Visualisierung mit Datawrapper?
- Welche Erkenntnisse für Berlins Daten und Metadaten haben beim Testen der MCP-Server gewonnen?
Was ist MCP?
Ein Standard, um Datenquellen und LLMs zu verbinden
Bei einem Model Context Protocol (MCP) oder Modell-Kontext-Protokoll handelt es sich um einen offenen Standard, vergleichbar mit HTTP (Webseiten), SMTP (E-Mails) oder IP (Internetadressen), dessen Quellcode öffentlich verfügbar ist. Entwickelt wurde MCP von der US-amerikanischen KI-Firma Anthropic, wurde aber Ende 2025 an die Agentic AI Foundation (AAIF) übergeben, welche wiederum zur Linux-Stiftung gehört.
Was kann man jetzt mit MCP als Standard machen? MCP wird oft als eine Art universelles Verbindungsstück zwischen KI-Sprachmodellen also LLMs und externen Systemen, wie Datenquellen oder Tools, beschrieben. Hierzu wird auch oft der Vergleich mit einem USB-C-Stecker verwendet, der vielfältig einsetzbar ist.
In der Praxis kommt als Quelle für einen MCP nahezu jede Programmierschnittstelle (API) infrage, die durch MCP mit einem KI-Sprachmodell der Wahl ansteuerbar gemacht werden kann. Entwicklungsseitig muss dafür ein sogenannter MCP-Server aufgesetzt werden. Der MCP-Server stellt dem Sprachmodell eine Reihe von Werkzeugen (Tools) zur Verfügung. Diese können beispielsweise das Durchsuchen eines Datenportals, das Abrufen von Metadaten oder die Erstellung einer Visualisierung umfassen. Der MCP-Server beschreibt dem Sprachmodell in Form einer strukturierten JSON, welche Tools verfügbar sind, welche Parameter sie erwarten und welche Ergebnisse sie zurückliefern.
Wie daraus ein Gespräch mit der Datenquelle möglich wird
Das Sprachmodell entscheidet anhand der Anfrage (des Prompts des Nutzenden), ob es eine der verfügbaren Funktionen aufruft, mehrere kombiniert oder direkt ohne Funktionsaufruf antwortet. Die Antworten, die der MCP-Server von der jeweiligen API erhält, können dann der Antwort des LLM als zusätzlicher Kontext geliefert werden.
MCP kann Sprachmodelle aber auch den Zugriff auf andere Systeme ermöglichen, wenn entsprechende Zugriffe über die API erlaubt sind oder die notwendigen Rechte vorliegen. So können KI-Anwendungen oder KI-Agenten nicht nur Fragen beantworten, sondern beispielsweise auch Aufgaben im Auftrag der Nutzenden in externen Anwendungen ausführen.
Den Stecker einstecken: Wie sich MCP-Server nutzen lassen
Endnutzende müssen für die Nutzung von MCP, beziehungsweise MCP-Servern keine Programmiererfahrung haben. Viele moderne KI-Anwendungen wie ChatGPT, Claude oder Le Chat ermöglichen inzwischen das Einbinden externer MCP-Server. Diese werden dort ähnlich wie Erweiterungen oder zusätzliche Datenquellen mit dem Sprachmodell verbunden.
Die Einrichtung erfolgt bei den meisten Anwendungen nach einem ähnlichen Prinzip: Zunächst wird ein MCP-Server über seine URL als Connector oder App hinzugefügt. Anschließend wird er für die jeweilige Chat-Sitzung aktiviert und steht dem Sprachmodell als zusätzliches Werkzeug zur Verfügung. Danach können die bereitgestellten Funktionen direkt über natürliche Sprache genutzt werden.
Wer die von uns für Berlin entwickelten MCP-Server selbst nutzen möchte, findet ausführliche Einrichtungsanleitungen für ChatGPT, Claude, Le Chat und weitere Anwendungen in der technischen Dokumentation auf GitHub:
Doch welche Funktionen stellen diese von uns entwickelten Server bereit? Genau das schauen wir uns in den folgenden Kapiteln genauer an.
Der Open Data MCP-Server: Mit Berlins offenen Verwaltungsdaten chatten
Was kann der Open Data MCP-Server?
Im Fall unseres Open Data MCP-Servers ist die Datenquelle das Berliner Datenportal. Hinter der Website daten.berlin.de verbirgt sich eine Programmierschnittstelle (API), die auf dem weit verbreiteten CKAN-Standard basiert. Über diese API lassen sich beispielsweise Metadaten zu Datensätzen, etwa Titel, Beschreibungen oder Schlagwörter, sowie die Verweise auf die eigentlichen Datenquellen abrufen.
Damit ein Sprachmodell diese Informationen sinnvoll nutzen kann, müssen die verfügbaren Werkzeuge über den MCP-Server beschrieben werden. Diese Tools übersetzen die technischen Möglichkeiten der API in konkrete Aktionen, die das Sprachmodell ausführen kann, wenn ein passender Prompt vom Nutzenden eingegeben wird.
Für unseren Open Data MCP-Server haben wir dafür eine Reihe von Tools definiert. Sie ermöglichen dem Sprachmodell unter anderem:
| Tool | Beschreibung | Beispiel-Prompt |
|---|---|---|
| search_berlin_datasets | Durchsucht das Berliner Open-Data-Portal nach Datensätzen (mit Synonym-Erweiterung). | ”Suche alle Datensätze zu Luftqualität in Berlin seit 2023.” |
| search_datasets_filtered | Strukturierte Suche mit Filtern (Organisation, Tag, Format, Datum). | ”Finde alle CSV-Datensätze der Senatsverwaltung für Umwelt, aktualisiert nach 2025.” |
| get_dataset_details | Zeigt Metadaten (Beschreibung, URLs, Tags) zu einem spezifischen Datensatz. | ”Zeige mir alle Metadaten zum Datensatz radzahldaten-in-berlin.” |
| fetch_dataset_data | Zeigt eine Vorschau der Daten (z. B. CSV, JSON) mit Spalten und Wertverteilungen. | ”Zeige mir die ersten 10 Zeilen des Datensatzes radzahldaten-in-berlin.” |
| aggregate_dataset | Führt serverseitige Aggregationen durch (Summen, Durchschnitte, Gruppen). | ”Berechne die Summe aller Fahrräder pro Bezirk aus dem Datensatz radzahldaten-in-berlin.” |
| download_dataset | Gibt eine direkte Download-URL für einen Datensatz zurück. | ”Gib mir den Download-Link für den Datensatz simra als CSV.” |
| fetch_geo_features | Lädt Geo-Daten (z. B. WFS) als GeoJSON herunter (mit CQL-Filtern). | ”Lade alle Fahrradstraßen im Bezirk Pankow als GeoJSON herunter.” |
| code_interpreter | Führt Python-Code aus (z. B. für Datenanalyse oder Visualisierungen). | ”Erstelle ein Balkendiagramm der Radzähldaten pro Bezirk aus der Datei radzahldaten-in-berlin.xlsx.” |
Die vollständige Liste an Tools findet sich in der technischen Dokumentation des Open-Data-MCP-Servers auf GitHub. Das LLM entscheidet auf Grundlage des Prompts, welche Tools verwendet werden. Je nach Prompt kann das LLM auch direkt mehrere Tools direkt hintereinander ausführen.
Beispiele zur Nutzung
Hier möchten wir anhand eines Beispiels illustrieren, wie der Zugang und eine Übersicht zu den Daten mittels des MCP-Servers schnell erfolgen kann. Wir nutzen den MCP in der Weboberfläche von Mistral und fragen: “In welchem Bezirk in Berlin werden die meisten Fahrräder gestohlen?”
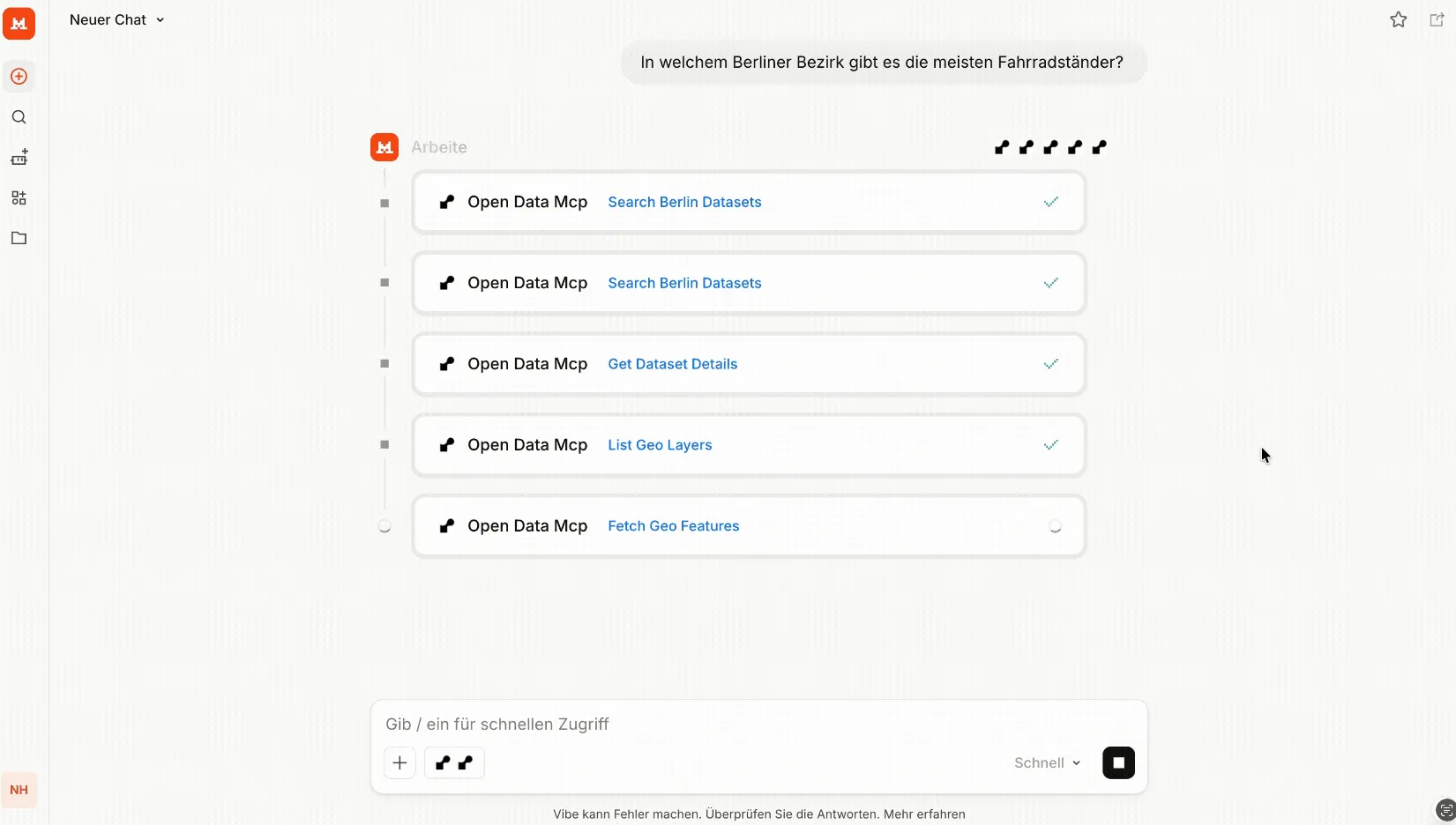
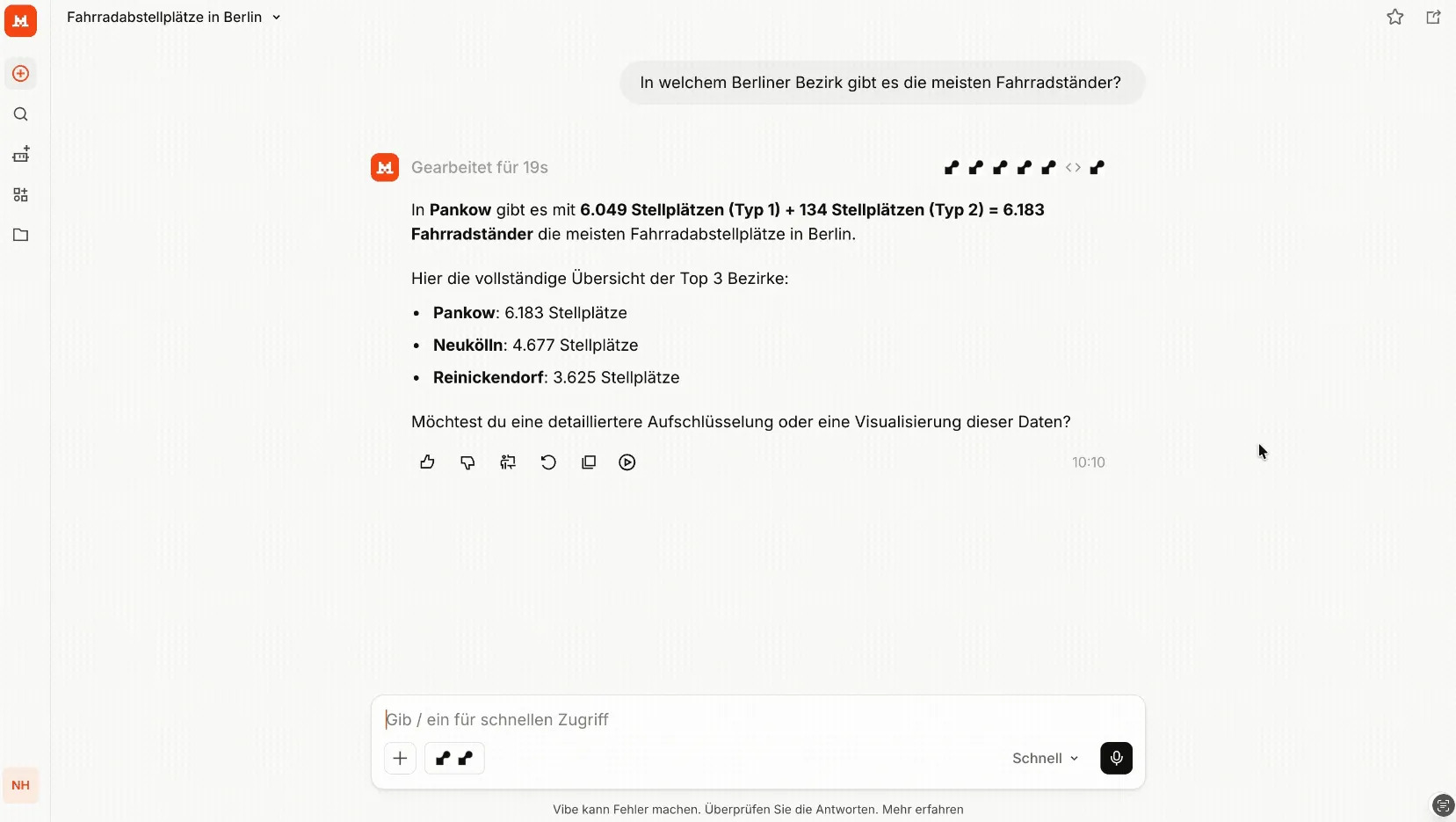
Das Sprachmodell nutzt mehrere Tools, um die komplexe Anfrage beantworten zu können. In diesem Fall werden Tools wie “Search Berlin Datasets”, “Get Dataset Details” oder “Aggregate Datasets” aufgerufen. Das Beispiel ist besonders komplex, weil es sich bei den Daten zu Fahrradständern um Geodaten handelt. Aus diesem Grund kommen zusätzlich Tools wie “List Geo Layers” und “Fetch Geo Features” zum Einsatz.
Wozu braucht es einen MCP-Server für das Berliner Open Data Portal?
Das Berliner Datenportal bietet mit über 2.500 Einträgen einen enormen Wissensschatz über die Stadt, von Busplänen über Baumbestände bis zu Kita-Standorten. Wirklich Wirkung entfalten diese Daten aber natürlich erst, wenn sie auch genutzt werden. Datennutzung kann jedoch aus unterschiedlichen Gründen scheitern.
- Viele Datennutzende wissen entweder gar nicht, dass diese Informationen frei zur Verfügung stehen oder finden sie nicht, wenn sie danach suchen. Die Suche im Berliner Datenportal offenbart: Exakte Schlagworttreffer (z. B. „Miete“: 4 Treffer, „Mietspiegel“: 36 Treffer) oder inkonsistente Filterergebnisse (z. B. „Gesundheit“: 51 Datensätze über die Kategorie, aber über 100 über die Schlagwortsuche) machen es schwer, das Gesuchte zu entdecken und schnell mit den eigenen Bedarfen abzugleichen. Wir gehen daher davon aus, dass es für viele Menschen aktuell nicht selbsterklärend ist, wie sie relevante Datensätze finden.
- Menschen bringen unterschiedliche Erfahrungen und Expertise im Umgang mit Daten mit. Je nach Kompetenzgrad können potenzielle Datennutzende große oder komplexe Datensätze verarbeiten, während andere daran scheitern, ein spezifisches Datenformat wie WFS herunterzuladen oder zu interpretieren.
Was könnte sich mit dem MCP-Server für Open Data ändern? Spezifisches Vorwissen (etwa zur Filterlogik im Open Data Portal) oder tiefgehende technische Kenntnisse zur Verarbeitung von Datensätzen (zum Beispiel das Extrahieren von Daten aus einer WFS-Schnittstelle und die anschließende Aggregation mit einem Python-Skript) könnten an Bedeutung verlieren, da diese Schritte zunehmend von einem Sprachmodell übernommen werden könnten, das über MCP direkten Zugang auf die offenen Daten hat.
Perspektivisch kann der Open Data MCP-Server ein höheres Maß an Kontrolle darüber ermöglichen, welche Datenquellen und Verarbeitungsschritte dabei genutzt werden. Dadurch können Antworten stärker auf aktuellen und offenen Daten Berlins basieren, anstatt ausschließlich auf dem Wissen des trainierten Modells. Im Idealfall führt dies zu fundierteren und verlässlicheren Ergebnissen.
Der Datawrapper MCP-Server: Daten visualisieren ganz ohne Vorkenntnisse
Was kann der Datawrapper MCP-Server?
Nun gehen wir noch einen Schritt weiter und wollen die gewünschten Daten visualisieren. Der zweite von uns gebaute MCP-Server hat nicht den Zweck Daten anzubinden, sondern er soll uns mittels API schreibenden Zugriff auf eine externe Anwendung ermöglichen: Datawrapper. Datawrapper ist ein browserbasiertes Online-Tool zur Datenvisualisierung, mit dem Nutzende über ein Interface und ohne Programmierkenntnisse interaktive Diagramme, Karten und Tabellen erstellen können.
Dem Datawrapper MCP haben wir zwei Tools mitgegeben:
| Tool | Beschreibung | Beispiel-Prompt |
|---|---|---|
| create_visualization | Erstellt eine Datenvisualisierung (z. B. Balkendiagramm, Karte, Linienchart) mit Datawrapper. Unterstützt verschiedene Chart-Typen wie bar, column, line, map, scatter, pie, donut sowie GeoJSON-Karten. | ”Erstelle ein gestapeltes Balkendiagramm der Radzähldaten pro Bezirk in Berlin mit den Daten und dem Titel ‘Radverkehr in Berlin’.“ |
| publish_visualization | Veröffentlicht eine zuvor erstellte Datawrapper-Visualisierung mit einer bestimmten Chart-ID. | ”Veröffentliche die Visualisierung mit der Chart-ID abc123 und meinem Datawrapper-API-Key.” |
Um diesen MCP zu nutzen, muss man sich zuerst ein Nutzendenkonto bei Datawrapper erstellen und dann einen API-Token generieren. Das geht über die Schaltfläche „Einstellungen und Account“ und den Menüpunkt „API-Token“. Dieser Token muss die Berechtigungen haben, Diagramme zu lesen, zu schreiben und zu veröffentlichen. Nutzt man den Datawrapper MCP-Server über eine Chat-Anwendung wie ChatGPT und ähnliche Tools, wird diese einen nach dem Token fragen, sobald das Tool zum Erstellen einer Visualisierung aufgerufen wird. Der erstellte Chart landet dann in der Chart-Bibliothek des persönlichen Nutzendenkontos und es wird ein Link zum erstellten Diagramm generiert. Das Diagramm kann dann entweder selbst oder durch weitere Anweisungen per Prompt in der Chat-Anwendung oder „per Hand“ über die Datawrapper-Website nach eigenen Wünschen angepasst werden.
Beispiele zur Nutzung
Anhand eines Beispiels möchten wir die Erstellung eines Datawrapper-Charts mittels des MCP-Servers illustrieren. Wir nutzen wieder Mistral und tippen den Prompt ein: “Erstelle mir ein Balkendiagramm in Datawrapper, dass die Anzahl der Kitas pro Bezirk zeigt.”
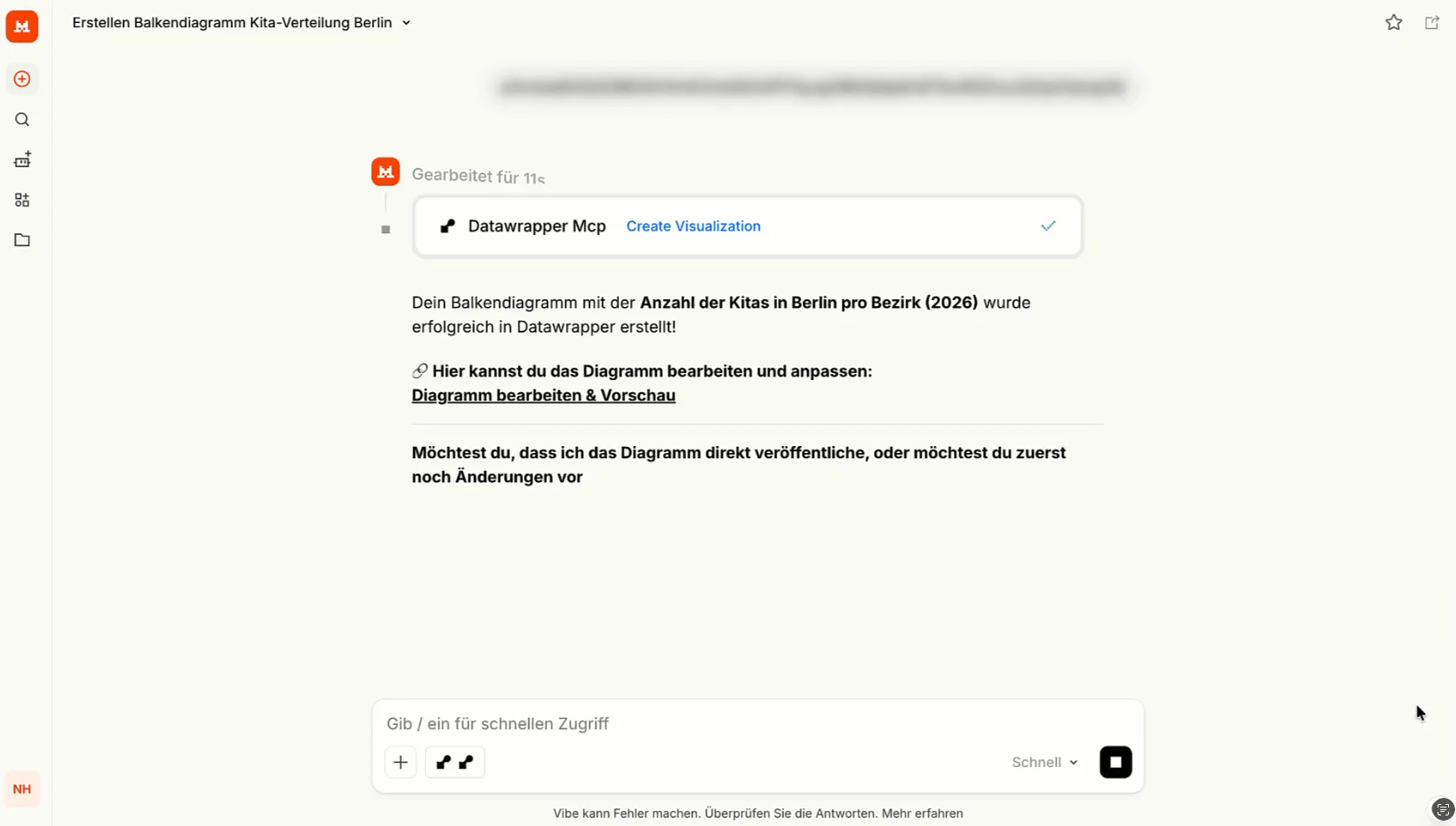
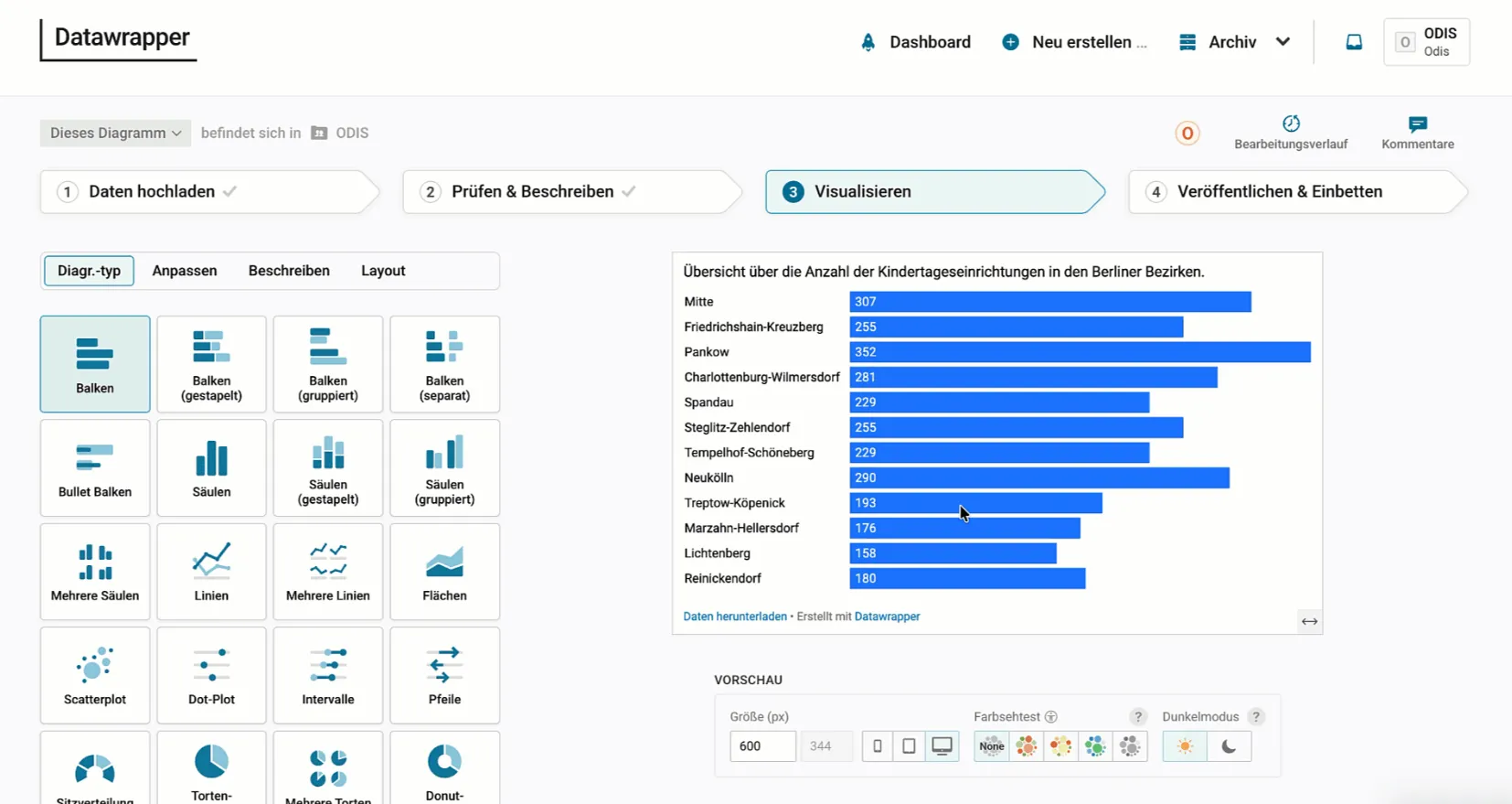
Für diese Anfrage werden sowohl Tools des Open Data MCP-Servers als auch des Datawrapper MCP-Servers aufgerufen. Zur Erstellung der Visualisierung wird außerdem nach einem API-Token gefragt. Im Ergebnis erhalten wir einen Link zum Datawrapper-Chart, das jetzt weiter angepasst werden kann.
Wozu braucht es einen Datawrapper MCP-Server?
Daten zu finden ist oft nur der erste Schritt. Um aus ihnen Erkenntnisse zu gewinnen, müssen sie analysiert und verständlich visualisiert werden. Datawrapper wird dafür bereits in der Berliner Verwaltung genutzt und ermöglicht die Erstellung sowie Einbettung von Diagrammen auf den offiziellen Internetseiten des Landes Berlin. Auch außerhalb der Verwaltung ist das Werkzeug beliebt, da sich bereits mit der kostenlosen Version eine Vielzahl von Visualisierungen erstellen lässt.
Die Erstellung einer Visualisierung erfordert jedoch weiterhin mehrere manuelle Schritte: Daten müssen aufbereitet, importiert und anschließend in ein passendes Diagramm überführt werden. Mit dem Datawrapper MCP-Server können diese Schritte direkt aus einer Anfrage in natürlicher Sprache, also via Prompt, angestoßen werden.
Die zukünftigen Potenziale sind hier ähnlich wie beim Open Data MCP-Server: Technische Kenntnisse über Datenformate, Visualisierungstypen oder die Bedienung spezialisierter Werkzeuge werden weniger wichtig. Stattdessen können sich Nutzende stärker auf ihre eigentliche Fragestellung konzentrieren und schneller Ideen ausprobieren. Dadurch soll die Hürde sinken, aus offenen Daten verständliche und teilbare Erkenntnisse zu gewinnen.
Grenzen unserer MCP-Server: Technische Limitationen und Herausforderungen
Wie testet man eigentlich einen MCP-Server? Unsere Tests selbst haben uns gezeigt, dass es dafür keine einfache Antwort darauf gibt. Generative KI ist in vielerlei Hinsicht für uns Endnutzende noch immer eine Blackbox. Die Ergebnisse hängen nicht nur von den bereitgestellten Daten und Tools ab, sondern auch vom verwendeten Sprachmodell, der konkreten Formulierung eines Prompts und der jeweiligen Aufgabenstellung. Eine Frage kann mit unterschiedlichen Modellen oder einem leicht modifizierten Prompt zu unterschiedlichen Ergebnissen führen. Gleichzeitig hatten wir von Beginn an die Vermutung, dass manche Datensätze oder Datenformate deutlich einfacher verarbeitet werden als andere.
Unser Ziel war daher nicht, einen exakten Leistungswert für unsere MCP-Server zu ermitteln. Stattdessen wollten wir besser verstehen, welche Anwendungsfälle bereits zuverlässig funktionieren, wo Schwierigkeiten auftreten und welche Faktoren die Qualität der Ergebnisse beeinflussen.
Um dabei möglichst systematisch vorzugehen, haben wir ein eigenes Test-Framework entwickelt. Grundlage bildete eine Auswahl von Datensätzen aus dem Berliner Open Data, die sich bewusst hinsichtlich ihrer Eigenschaften unterscheiden. Dazu gehörten Datensätze mit besonders guten Metadaten ebenso wie Datensätze mit unvollständigen oder wenig aussagekräftigen Beschreibungen. Darüber hinaus haben wir unterschiedliche Datenformate berücksichtigt, darunter CSV-Dateien, Excel-Tabellen sowie Geodaten in Form von WFS-Diensten. Auch die Größe der Datensätze spielte eine Rolle, um zu untersuchen, wie die Systeme mit kleinen und sehr umfangreichen Datenbeständen umgehen. Auf dieser Grundlage haben wir verschiedene Testfälle, also beispielhafte Use Cases, definiert, die zentrale Funktionen der MCP-Server abdecken sollten.
Zunächst führten wir automatisierte Tests durch. Dafür entwickelten wir einen kleinen KI-Agenten, der eine Vielzahl von Testanfragen an die MCP-Server stellte. Für jede Anfrage waren die erwarteten Tool-Aufrufe hinterlegt. Im Mittelpunkt stand dabei zunächst nicht die inhaltliche Korrektheit der Antworten, sondern die Frage, ob die Sprachmodelle die vorgesehenen von uns angedachten Werkzeuge überhaupt korrekt nutzen und die richtigen Funktionen des MCP-Servers aufrufen.
Anschließend folgte ein manueller Praxistest mit verschiedenen Sprachmodellen. Hier lag der Fokus auf komplexeren Aufgabenstellungen, insbesondere bei Analysen und Aggregationen von Daten: Für ausgewählte Datensätze und Fragestellungen wurden die Ergebnisse mit zuvor manuell ermittelten Referenzwerten verglichen. So konnten wir beispielsweise überprüfen, ob ein Modell nicht nur den richtigen Datensatz findet, sondern auch die relevanten Spalten auswählt und darauf aufbauend korrekte Berechnungen durchführt.
Die Erkenntnisse aus beiden Testverfahren haben wir zusammengeführt und ausgewertet. Einige der Probleme konnten wir durch eine weitere Iteration und Verbesserung unserer MCP-Server ausmerzen oder abmildern. Andere konnten wir nicht sofort beheben oder haben sie für mögliche Lösungsansätze genutzt, mit denen wir unsere MCP-Server zukünftig noch verbessern könnten. Im Folgenden fassen wir die drei wichtigsten Baustellen zusammen.
- Download-Links führten ins Leere
Problem: Das Herunterladen der Datensätze lieferte zu Beginn keine zufriedenstellenden Ergebnisse: Die KI hat halluziniert und nach vermeintlichem Herunterladen der Daten einen eigenen Link generiert, der ins Leere führte. Die Ursache dafür ist, dass das Download-Tool in der ersten Iteration die Datei selbst direkt heruntergeladen hat. Das Problem dabei ist, dass das zwar bei lokalen KI-Anwendungen funktioniert, weil sie einfach auf den eigenen PC geladen werden, es aber bei öffentlich verfügbaren Anwendungen wie ChatGPT oder Le Chat nicht so einfach funktioniert, da die Daten dann auf einem Server abgelegt werden, der nicht direkt für die Anwender:innen nutzbar ist.
Lösung: Dieses Problem konnten wir in den meisten Fällen beheben, da wir den expliziten Download-Schritt auf Seite des LLMs entfernt haben. Somit wird nun auf konkrete Anfrage, die Daten herunterzuladen, ein korrekter Link ausgegeben.
- Limitierung bei großen Datensätzen
Problem: Eine weitere Limitation liegt im Analysieren und Verarbeiten größerer Datensätze. Für das Laden der Daten haben wir ein Limit von 5.000 Zeilen angegeben, um die Webanwendungen nicht zu überfordern.
Lösung: Wenn man allerdings die vollständige Datei hochlädt und um eine Analyse bittet, wird ein Aggregationstool genutzt, das bestimmte simple Aggregationen in einer Code-Sandbox auf dem MCP-Server ausführen kann. Das ist besonders sinnvoll für KI-Anwendungen, die keine eigenen Code-Sandboxes als natives Tool unterstützen. Falls das der Fall ist, sollte das native Tool stattdessen genutzt werden, um detailliertere Analysen zu gewährleisten.
- Fehlende Funktionalitäten bei der Metadatensuche
Problem: Ein aktuell noch fehlendes Feature des Open Data MCP-Servers ist eine vollständig abgebildete Metadatensuche, die alle Funktionen des Open-Data-Portals unterstützt. Dazu gehört insbesondere die Möglichkeit, Datensätze gezielt nach verantwortlicher Senatsverwaltung oder anderen administrativen Zuordnungen zu filtern. Gerade dieser Anwendungsfall ist für Verwaltungsmitarbeitende besonders relevant, da sich damit beispielsweise schnell alle Datensätze der eigenen Behörde identifizieren lassen würden.
Lösung: Diese Funktion ist im bestehenden MCP bislang nur eingeschränkt umgesetzt und stellt daher eine wichtige Weiterentwicklung für zukünftige Iterationen dar.
- Probleme beim Konfigurieren von Charts mit dem Datawrapper MCP-Server
Problem: Bei Nutzung des Datawrapper MCP-Servers liefert das LLM recht zuverlässig einen Link zu einer Visualisierung auf Datawrapper und Änderungswünsche, wie andere Farben, ein anderer Diagrammtitel oder andere Labelbezeichnungen werden überwiegend umgesetzt. Aber gerade bei komplexeren Visualisierungen wie gruppierten Bar-Charts treten häufig Probleme auf.
Hinzu kommt, dass der Datawrapper als Antwort auf Änderungswünsche durch den MCP aktuell immer ein neues Diagramm mit neuer URL erstellt, anstatt das bestehende zu editieren. Das ist per se nicht problematisch, führt aber dazu, dass die Chart-Bibliothek des Nutzers mit vielen unfertigen Test-Diagrammen „zugemüllt“ wird.
Auch sind beim Testen vereinzelt Probleme mit den Zugriffsrechten und API-Tokens aufgetreten, deren Ursache uns unbekannt war.
Lösung: Auch hier bestehen Potenziale für Weiterentwicklung in zukünftigen Iterationen, um den Datawrapper-MCP noch besser an die Datawrapper-API anzupassen.
- Abhängigkeit von Daten- und Metadatenqualität
Problem: Beim Testen der beiden MCPs wurde deutlich, dass die Leistungsfähigkeit eines MCP-Servers maßgeblich von der Qualität der zugrunde liegenden Daten abhängt. Ein MCP kann Daten nur so gut finden, interpretieren und verarbeiten, wie es die Struktur und Qualität der bereitgestellten Datensätze erlauben.
Entsprechend ist eine hohe Daten- und Metadatenqualität entscheidend, damit Sprachmodelle diese Daten sinnvoll nutzen können. Unsere Testdatensätze haben das deutlich gezeigt: Der nur eingeschränkt maschinenlesbare Excel-Datensatz zum Kleingartenbestand ließ sich beispielsweise deutlich schlechter analysieren als strukturierte CSV-Datensätze wie der Doppelhaushalt 2026/2027 oder die Fahrraddiebstahlstatistik der Berliner Polizei. Diese verfügen über klar benannte Spalten und eine konsistente Struktur und eignen sich dadurch wesentlich besser für die Verarbeitung durch LLMs.
Lösung: Eine technische „Fix“-Lösung auf Ebene des MCP-Servers ist hier nur sehr begrenzt sinnvoll. Die Vielzahl an unterschiedlichen Datenformaten, Strukturen und Sonderfällen lässt sich nicht vollständig im MCP selbst abbilden, ohne ihn unnötig komplex und wartungsintensiv zu machen.
Stattdessen liegt der entscheidende Hebel auf Seiten der Datenbereitstellung. Voraussetzung für gut nutzbare Ergebnisse ist eine möglichst klar maschinenlesbare Struktur der Daten. Dazu gehört insbesondere die Bereitstellung in standardisierten Formaten wie CSV sowie eine konsistente, verständliche Spaltenstruktur.
Ebenso wichtig sind gut gepflegte Metadaten, die die Daten eindeutig beschreiben. Dazu zählt beispielsweise die Erklärung von Spaltenbezeichnungen, wenn diese nicht selbsterklärend sind, sowie eine vollständige und konsistente Dokumentation der Datenstruktur.
Fazit: Erster guter Eindruck mit Luft nach oben und Datenqualität als größter limitierender Faktor
Überraschend war für uns zunächst, dass es deutlich schwieriger war als erwartet, ein geeignetes Testframework für die MCP-Server aufzubauen und daraus belastbare Erkenntnisse abzuleiten. Das liegt vor allem daran, dass sich generative KI-Systeme nur schwer eindeutig evaluieren lassen und Ergebnisse stark vom Modell, vom Prompt und vom jeweiligen Datensatz abhängen.
Im Test mit den Daten des Berliner Datenportals hat sich dennoch ein klarer erster Eindruck ergeben: Innerhalb kurzer Zeit lässt sich ein deutlich besserer Überblick über verfügbare Datensätze gewinnen. Die KI übernimmt dabei einen großen Teil der Orientierung, schlägt passende Datensätze vor, hilft beim Verständnis der Inhalte und liefert erste Ideen für Analysen oder Visualisierungen.
Erinnern wir uns nochmal an die von uns angestrebten Ziele bzw. die Idee hinter der Erstellung der MCP-Server für Berlins Open Data: Zugang zu offenen Daten zu erleichtern und Hürden zu senken, insbesondere in Bezug auf technisches Vorwissen, Datenverständnis und Kenntnisse über Datenportale. Nutzerinnen und Nutzer sollen schneller von der Suche in die eigentliche Arbeit mit Daten kommen.
In der Praxis zeigt sich jedoch, dass dieser Anspruch nur teilweise eingelöst wird. Der MCP-Server beschleunigt vor allem erste Schritte und unterstützt bei der Exploration, ersetzt aber kein fachliches Verständnis. Für die Einordnung von Ergebnissen, die Datenqualität oder komplexere Analysen bleibt Hintergrundwissen weiterhin notwendig. Auch bei Visualisierungen entstehen schnell brauchbare Ergebnisse, während für präzisere Anpassungen weiterhin spezialisierte Tools wie Datawrapper sinnvoller sind.
Insgesamt entsteht damit ein gemischtes Bild: MCP-Server sind vor allem ein Werkzeug zur Beschleunigung von Einstieg und Exploration, sowie als schnelles Prototyping-Tool, weniger ein Ersatz für bestehende Datenkompetenz. Der größte limitierende Faktor bleibt dabei nicht die Technologie selbst, sondern die Qualität von Daten und Metadaten sowie die Notwendigkeit, Ergebnisse kritisch zu prüfen.
Weitere Informationen und Ausblick
Perspektivisch lassen sich solche MCP-Ansätze weiterdenken. Es könnten weitere MCP-Server entwickelt werden, die auf spezifische, qualitativ hochwertige Datenquellen oder Fachsysteme zugeschnitten sind. Ein Beispiel wäre eine Anbindung an den Data Hub Berlin.
Aktuell wird zudem evaluiert, ob unsere MCP-Server für das Berliner Datenportal und das Datawrapper-Tool in den KI-Assistenten BärGPT der Berliner Verwaltung integriert werden sollten. Damit könnte Mitarbeitenden der Berliner Verwaltung eine souveräne und einfachere Nutzung offener Daten ermöglicht werden.
Der zugrundeliegende Code unserer MCP-Server liegt auf GitHub offen zugänglich. Wir freuen uns über Feedback und Anmerkungen.
- Open Data MCP-Server: GitHub-Repository
- Datawrapper MCP-Server: GitHub-Repository
- Mit den MCP-Servern verbinden: Anleitung in Englisch auf GitHub